
High-performance computing with Ubuntu
| Please consider subscribing to LWN Subscriptions are the lifeblood of LWN.net. If you appreciate this content and would like to see more of it, your subscription will help to ensure that LWN continues to thrive. Please visit this page to join up and keep LWN on the net. |
Jason Nucciarone and Felipe Reyes gave back-to-back talks about high-performance computing (HPC) using Ubuntu at SCALE this year. Nucciarone talked about ongoing work packaging Open OnDemand — a web-based HPC cluster interface — to make high-performance-computing clusters more user friendly. Reyes presented on using OpenStack — a cloud-computing platform — to pass the performance benefits of one's hardware through to virtual machines (VMs) running on a cluster.
Open OnDemand
High-performance computing is, according to Nucciarone's slides: "A paradigm where you use supercomputers, computing clusters and grids to solve advanced scientific challenges." Nucciarone — a self-described "not so ancient elder of Ubuntu HPC" — has been involved with Ubuntu's HPC community team since it formed in the wake of the 2022 Ubuntu summit. At that event, participants from Canonical and Omnivector noticed that they were facing a lot of the same problems trying to package software for use on HPC clusters, and formed the community team to try and address that. Nucciarone called for people to join the group if they think it's interesting, even if they are not currently doing any HPC work.
![[Jason Nucciarone]](https://static.lwn.net/images/2024/Jason_Nucciarone-small.png "Jason Nucciarone")
He moved on to the main focus of the talk by asking why, even though HPC users are "bright and smart people", they often have trouble taking full advantage of an HPC cluster. He gave some examples of commonly touted reasons, such as the fact that HPC clusters often use different tech stacks, or that the system is "too advanced". None of those are the main problem he sees. "The main problem is this: the terminal."
HPC clusters are often organized with a pool of worker nodes where jobs are sent. Users do not connect to workers directly, but rather to a "head node" or "jump host" that provides them with tools to manage the cluster. When a new HPC user connects (invariably via SSH) to the head node of a cluster, they are presented with a shell prompt. Nucciarone pointed out four problems with this: affordances, learnability, consistency, and visibility. Firstly, the terminal doesn't tell the user what it can do. This makes discovering what the system is capable of difficult. Secondly, the languages involved in running an HPC system all have their own learning curve. Becoming simultaneously proficient in bash, Python, and any other programming languages in use on the cluster is a tall order. Thirdly, each tool has its own interface and command-line conventions. Learning the interface of one tool does not guarantee a user can transfer that knowledge to another tool. Finally, the shell just provides a user with a blank prompt, it doesn't guide them toward what to do next. "How do you learn what you don't know if you don't know what you don't know?"
Nucciarone's proposed solution to this is Open OnDemand, "an interactive portal for accessing HPC resources over the internet". He also described it as a "web-based application that moves beyond the terminal" and that "focuses on providing a visual interface for accessing your HPC resources". The benefits of using Open OnDemand include the ability to use interactive applications like notebooks, compatibility with many existing cluster scheduling systems, and even the capacity to "launch a desktop session directly on your cluster" (enabling users to run graphical applications on the cluster), he said.
The Ubuntu HPC team has been working to develop "Charmed HPC", a system to make deploying HPC clusters from scratch much easier using Juju. Open OnDemand could tie into that by providing a better user interface for users out of the box. For that to work, though, Open OnDemand needs to be packaged for Ubuntu, which is what Nucciarone is currently working on.
He has been writing a snap that runs all the services required for Open OnDemand. He gave a demo showing how this makes spinning up the Open OnDemand web interface as simple as installing the snap and then starting the service. Actually using the web interface for anything requires having a correctly configured HPC cluster already set up to connect to, of course.
Nucciarone is currently working on OpenID Connect integration and sorting out some internal problems with Open OnDemand. One particular difficulty has been packaging the custom versions of the Apache and NGINX web servers that Open OnDemand requires. When asked why both were needed simultaneously, Nucciarone replied: "To be honest, it's not quite clear to me myself". He went on to say that that was how the upstream project had it, and that a lot of their tooling is built around using Apache.
Once his work on fixing the last few problems is finished, he plans to make the snap available in the Snap Store. In the future, he wants to add built-in support for a base set of interactive web applications, and write a Juju operator for easy deployment. Nucciarone ended his talk by once again asking people to join the Ubuntu HPC team.
OpenStack
Reyes's talk was aimed at a slightly different audience. He talked about how to use OpenStack — an infrastructure-as-a-service platform which can be used to configure HPC clusters — to get the most performance out of a cluster. OpenStack allows users to run virtual machines on a cluster, transparently handling the setup of networking, migration of workloads, etc.
![[Felipe Reyes]](https://static.lwn.net/images/2024/Felipe_Reyes-small.png "Felipe Reyes")
He described the relevant components of an OpenStack cluster, and pointed out that everyone has different metrics that they care about optimizing. Different people will care about throughput, CPU usage, latency, etc. He also showed a diagram from Brendan Gregg of the myriad performance-observation tools that we have to keep track of these things.
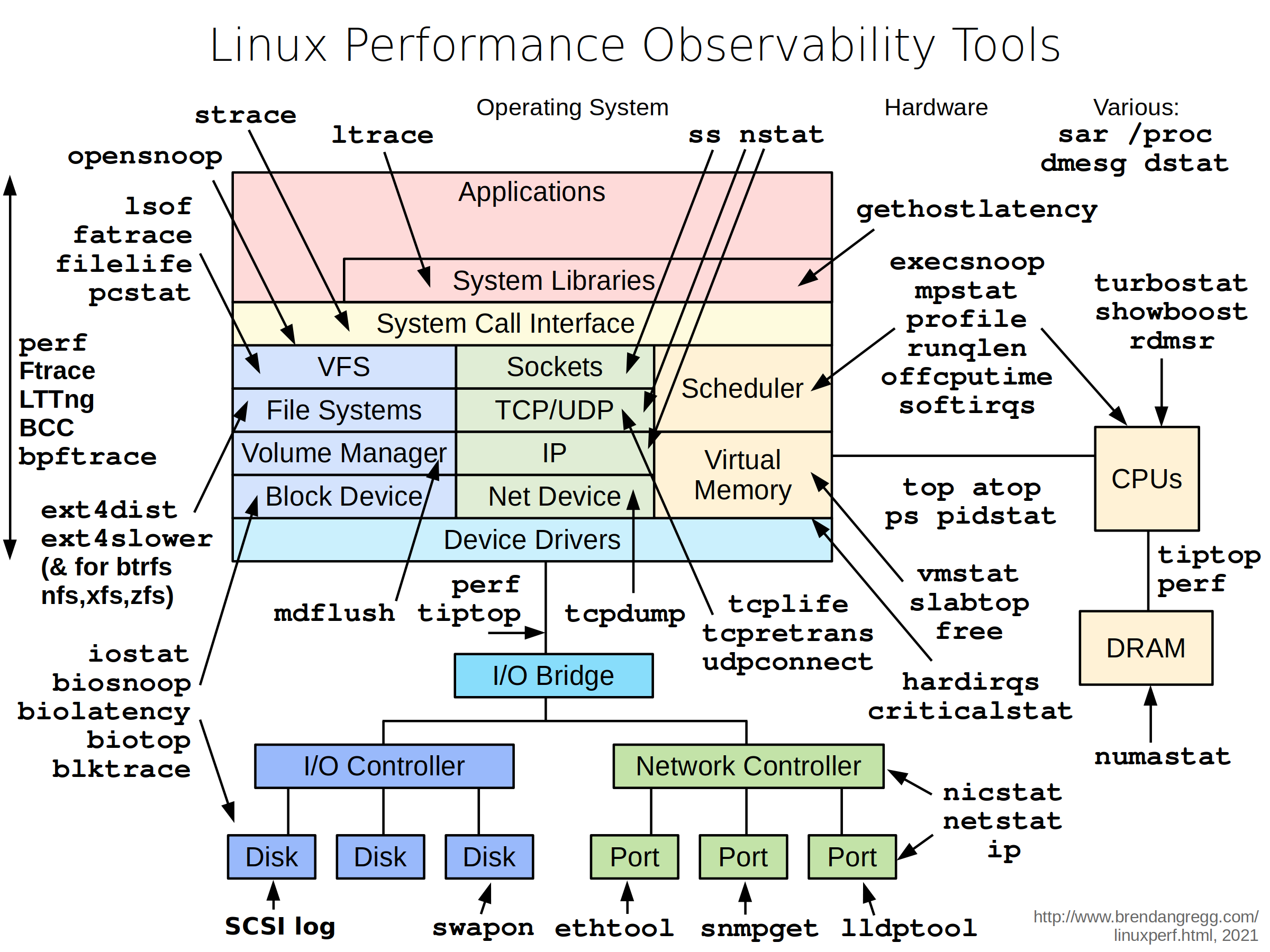{kind=link}
There are a number of different configuration options that users of OpenStack have available to fine-tune the performance of their clusters. Reyes explained how one can create "flavors" — particular types of node available on a cluster, fine-tuned to a particular workload. "You may have a fleet of nodes, and those nodes may have different properties", he explained. Segmenting nodes with a particular property (for example, solid-state drives) into a separate flavor can help the scheduler to decide where a VM running on the cluster ought to be assigned.
Once nodes have been split into flavors, the rest of the settings he discussed can then be applied per-flavor. The general theme of the options is making the virtualized hardware that is available to the VM map as closely as possible to the underlying physical hardware, to avoid overhead. Reyes summed this up as trying to get a "good representation so the hardware can be taken advantage of".
In pursuit of this, flavors can specify the number of sockets, cores, and threads made available for each VM. Those virtual CPUs can then be pinned, to ensure that specific physical CPUs are used for each virtual CPU. If no other VMs have access to those CPUs, this will ensure that only the configured VMs can run there. This isn't sufficient to give full control of the CPUs to the VM, though. The host kernel could still choose to run kernel tasks on those CPUs. To solve this, Reyes recommended adding the isolcpus command line option, to instruct the Linux kernel not to schedule tasks on those CPUs. "This gives you the guarantee that any VMs [...] are not competing for resources."
He also noted that OpenStack supported configuring Non-Uniform Memory Access (NUMA) for each flavor. Usually, the kernel picks up information about the NUMA configuration of a machine from the hardware. By configuring the virtual hardware of the VM to match the real NUMA properties of one's cluster, one can let the kernel take advantage of its NUMA optimizations. By default, VMs have only one NUMA node, but one can configure a more-specific setup, including the ability to "create asymmetric definitions".
During the Q&A session, Nucciarone asked what could be done to improve the documentation of these options, so that people running private clusters know what they need to do. Reyes responded that the documentation was indeed a problem, and "makes a lot of assumptions", ultimately suggesting that it could be improved by adding more pointers to other places where people can learn about concepts like NUMA.
Another member of the audience asked whether the documentation should include example use cases. Reyes agreed with the spirit of the request, but said that it was tricky because people sometimes take examples in documentation as golden rules that they can copy and paste without understanding. "If you don't understand the characteristics of the things you're running, it's better to stay in the defaults". This led to some discussion, with a different member of the audience saying: "No default works well for everyone".
Ultimately, the configurations Reyes discussed are highly specialized, and probably best employed by people who already know how details like NUMA and CPU-pinning work. He was clear that while these options offered fine control over the performance characteristics of hosted VMs, there is no substitute for actually measuring the performance characteristics one is interested in improving.
Conclusion
High-performance computing is a challenging industry. Despite that, people are putting significant effort into making Ubuntu more useful as a platform for building an HPC cluster. Future developments are likely to be reported on Ubuntu's HPC Blog or discussed on the Ubuntu Discourse forum.
[I would like to thank LWN's travel sponsor, the Linux Foundation, for travel assistance to Pasadena for SCALE.]
| Index entries for this article | |
|---|---|
| Conference | Southern California Linux Expo/2024 |
(Log in to post comments)
High-performance computing with Ubuntu
Posted Mar 28, 2024 10:16 UTC (Thu) by aragilar (subscriber, #122569) [Link]
High-performance computing with Ubuntu
Posted Mar 28, 2024 21:30 UTC (Thu) by gmgod (subscriber, #143864) [Link]
As for the OnDemand thingy, in an Academic setting, I've seen a lot of excitement... that dies out in a month or so as it gets religiously ignored. People like the idea of a more discoverable interface (they say "better UX" but that's what is meant) until they "discover" everything they need and they start to get shit done... which requires the versatility of the shell because nobody's gonna write an OnDemand workflow for their particular use, if there is one main "workflow" at all...
Anyway, HPC needs a refresh. MPI is an old interface, making it work is clunky, and not well standardized. We need a better cpu-vectorization story (one lib/program that aitomatically makes use of vector instructions/hardware without need to recompile like fftw or openblas have done forbmore than a decade)... There is also a lot of software out there that would benefit from using modern coding practices and user experience principles...
But I struggle to think of a computational domain where all that's needed is pure, routine, reproducible, number crunching where all the performance trade-offs and interpretations are so well understood that a one-size-fits-all approach would work...
Actually that's not true... What I've just described is what most tools do already... And if not already, the "simulation guy" has already written that 30-line script that does everything required already...
I don't want to spit too much on OnDemand because it's coming from a good place and they mean well. It's probably just a bit misguided.
High-performance computing with Ubuntu
Posted Apr 15, 2024 15:15 UTC (Mon) by nuccitheboss (guest, #170927) [Link]
A cool thing that I've learned through attending OnDemand user group sessions and speaking with various advocates, developers, and institutions is how OnDemand is being used to teach the next generation of researchers (high schoolers, early-career professionals, undergraduates, etc.) how to use supercomputers. One interesting example that really stuck with me was an after-school high school was having students submit jobs and visualize data from iPads using Open OnDemand. Their reasoning was that much of gen alpha/gen Z is more used to using touch-based devices than they are traditional computers, and engaged better with the material when using devices that were much more familiar to them than traditional desktop workstations.
OnDemand won't always be the right fit in every situation, but I do think that it has made leaps and strides at improving the onboarding experience for new people coming into the HPC ecosystem, and it is powerful tool for developing your workflows before submitting off to the scheduler. I'm excited for the further improvement they're adding to the 3.x series to improve the process of developing workflows.
High-performance computing with Ubuntu
Posted Mar 28, 2024 12:27 UTC (Thu) by ejr (subscriber, #51652) [Link]
High-performance computing with Ubuntu
Posted Apr 15, 2024 15:18 UTC (Mon) by nuccitheboss (guest, #170927) [Link]
The fun I have been having is integrating additional features such as automatic snapshotting of OnDemand so that it's dead-simple for *anyone* to backup and restore their installation, and making it easy for folks to configure the policies and integrate the different components. It might take a few cycles, but I'm confident that we can make something that works for at least 80% of people, and something that the 20% can customize according to their needs :)
High-performance computing with Ubuntu
Posted Mar 31, 2024 19:23 UTC (Sun) by gray_-_wolf (subscriber, #131074) [Link]
I would have hoped there would be some recommended manual to read.
High-performance computing with Ubuntu
Posted Mar 31, 2024 22:14 UTC (Sun) by ceplm (subscriber, #41334) [Link]
High-performance computing with Ubuntu
Posted Apr 15, 2024 15:15 UTC (Mon) by nuccitheboss (guest, #170927) [Link]
I personally haven't found the "golden" resource that I would want to point someone to that serves as the "how to learn if you don't know what you don't know" for HPC (or just life in general). I've personally found the best teacher to be failure and getting raked over hot coals on the internet, however, that's difficult to sum up in a blog post. A good starting point I found for when I do training sessions and/or workshops is to clearly define what the end goal is. At that point it's easier to identify the challenges the less-experienced professionals will likely stumble across, but that process requires a more experienced mentor.
Maybe I'll start a blog and muse on the topic for HPC.
High-performance computing with Ubuntu
Posted Apr 4, 2024 11:33 UTC (Thu) by rfehren (guest, #120494) [Link]
High-performance computing with Ubuntu
Posted Apr 15, 2024 15:59 UTC (Mon) by nuccitheboss (guest, #170927) [Link]
*Totalitarianism and centralization are not a good things.* If anything, it really only enables those who hold the power to shut down the ones that they feel threatened by rather than attempting to improve. What I love about the open source ecosystem is that just because someone else got their first doesn't entitle them to it. I personally enjoy going to conferences and user group meetings and be able to compare notes with folks from Spack, EasyBuild, OnDemand, Red Hat, CIQ, SUSE, OpenHPC, OCHAMI, Kubernetes SIGs, OpenStack Scientific SIG, etc. We all have different priorities, but that doesn't stop us from exchanging ideas and identifying areas for collaboration. The convergence of cloud and HPC is a huge topic in HPC, and I'm excited to see everyone trying new things and I like talking about it.
Innovation in a field like HPC requires groups of individuals who have ambition and are willing to experiment, not a central authority who gets to decide how it all unfolds.