
LWN.net Weekly Edition for March 28, 2024
Welcome to the LWN.net Weekly Edition for March 28, 2024
This edition contains the following feature content:
- GNOME 46 puts Flatpaks front and center: the GNOME project is making a new feature-filled release.
- High-performance computing with Ubuntu: the Ubuntu project is working on several things to make high-performance computing easier.
- Hardening the kernel against heap-spraying attacks: the kernel may be getting changes to its memory management to make certain attacks harder.
- The rest of the 6.9 merge window: the kernel receives several large updates for 6.9.
- Nix at SCALE: four short talks about the Nix project: Using Nix to build Docker images; using systemd in the early boot on NixOS; defined service interfaces; and an overview of the current state of Nix.
This week's edition also includes these inner pages:
- Brief items: Brief news items from throughout the community.
- Announcements: Newsletters, conferences, security updates, patches, and more.
Please enjoy this week's edition, and, as always, thank you for supporting LWN.net.
GNOME 46 puts Flatpaks front and center
The GNOME project announced GNOME 46 (code-named "Kathmandu") on March 20. The release has quite a few updates and improvements across user applications, developer tools, and under the hood. One thing stood out while looking over this release—a major emphasis on Flatpaks as the way to acquire and update GNOME software.
Improvements
One of the headline features for GNOME 46 is its global search feature, but it requires some tweaking before it becomes as useful as it could be. Users can now bring up the global search by pressing the Super key (the key with a Windows symbol on many keyboards), Ctrl+Shift+F, or by clicking the Activities button in the top bar, provide a search term and the global search feature will display results from installed applications, GNOME's settings, installable applications in the software store, contacts in the GNOME address book, and any matching files. Well, any matching files that are in directories that GNOME has been configured to search.
Weirdly, search is only set up to look through a handful of directories by default, which is not quite what one would expect. A user would likely expect all of the files in their home directory to be part of a global search, but this is not the case. GNOME will search a user's home directory at the top level, plus Documents, Downloads, Music, Pictures, and Videos. If one wants GNOME to search, say, ~/src, then it's necessary to add ~/src specifically as a search location. Once configured to peek into the proper directories, search works quickly and well, but it's not intuitive to have to specify each subdirectory.
The project has also refactored Files (or Nautilus, as it used to be known) to improve performance. (An example of that work is here.) Prior to GNOME 46, Files would be noticeably slow when viewing a directory with, say, a lot of photos. For example, I have one directory with 1,188 JPEGs, a total of 9.8GB of photos. It would take Files quite a while to render the thumbnails for the images, which felt sluggish. Not unusable, but definitely slow even on a recent system with an NVMe drive and 64GB of RAM. Using Files with the improvements in this release feels much faster.
![[The GNOME 46 desktop]](https://static.lwn.net/images/2024/GNOME-46-sm.png "The GNOME 46 desktop")
Touchpad settings have gotten a few new options that may make laptop users happy. One of the worst things about early touchpad use on Linux was accidentally sending the pointer skidding across the desktop while typing, and possibly switching application focus accidentally. A setting was eventually added to disable the touchpad while typing, which makes it much easier to write while sitting on the couch. But, some applications call for a combination of key presses and touchpad movement—so users can now turn that feature off if needed.
The touchpad settings also picked up new options for right-clicking (also called "secondary click"), so users can choose whether they prefer to cause a right-click with two fingers or by tapping a corner of the touchpad.
One of the ways GNOME tries to simplify life for users is by providing an easy way to connect to online services, and to share those connections with its applications. For example, users can provide access to a Google account to give GNOME's applications access to Gmail, Google Calendar, and files stored in Google Drive. Users set up access to these services using the online accounts settings. The supported account types have changed over time, but recent releases include support for email (SMTP/IMAP), Nextcloud, Google accounts, Microsoft Exchange, and Kerberos login.
GNOME 46 has added support for Microsoft OneDrive file storage, and support for the WebDAV (file access), CalDAV (calendar), and CardDAV (contacts) protocols. If users connect to a Microsoft 365 account, they will now see files stored in OneDrive in the files application as if they were local files and directories. Unfortunately, I had no success in setting up a connection to any of Fastmail's WebDAV, CalDAV, or CardDAV services.
Showcasing Flatpak
On top of the default applications included with a standard GNOME install, the project has a showcase of applications called GNOME Circle. There are several new applications in the Circle for GNOME 46. These new applications include a lightweight to-do application called Errands, a minimal audio player called Decibels, an image cropping and conversion tool called Switcheroo, and an ASCII-art generator called Letterpress, which is an amusing tool, and it does generate some impressive ASCII artwork. By default it generates images at a "resolution" of 100 characters, but can go up to 500 characters wide. Another new entry is Railway, an application that provides travel information for users who are fortunate enough to live in areas with decent train service. It is, sadly, an application that is of little use in Durham, North Carolina.
Aside from showcasing GNOME libraries and technologies, the Circle applications also move users in the direction of installing software from Flathub. GNOME's Software utility allows users to browse a curated list of software available on a Linux distribution. It is a front-end for PackageKit, and supports RPMs and Debian packages (depending, of course, on the underlying distribution) and Flatpaks.
All of the applications announced with GNOME 46 are only available in the Store application as Flatpaks, at least right now. Most of the older applications in GNOME Circle also seem to be available only as Flatpaks, though a handful of older applications like the Déjà Dup backup tool are still available as RPMs on Fedora.
Some applications advertise that they are only available as Flatpaks. Biblioteca, an offline
viewer for GNOME's developer reference materials, warns that "Biblioteca
is made possible by Flatpak. Only Flathub Biblioteca is
supported.
" The same is true of the Workbench
application for prototyping GTK and GNOME applications. The
applications are open source (GPLv3) and nothing would prohibit a
distribution from providing native packages, but it's interesting how
emphatic the maintainers are about a Flatpak-only distribution model.
GNOME 46 includes a few other changes that seem designed to
encourage Flatpak use over native distribution packages. The first is
showing a verified
badge, which indicates that the application on Flathub is published by the original
developer or a "third party approved by the developer
". The verification
process requires developers to put a verification token on the
responsible organization's web site or the source code hosting site
(e.g., GitHub or GitLab) in a repository the developer owns, or the
developer needs to be an administrator or owner of the organization or group that owns
the repository.
For example, if a developer for Acme Corp wanted to verify an application they would need to place the token on the web at
https://acme.com/.well-known/org.flathub.VerifiedApps.txt
The token is simply a unique string of characters like 00000000-aaaa-0000-aaaa-000000000000. An organization can include multiple verification tokens in the text file if it is responsible for more than one application.
The manual process would make it hard to get a verified badge on Flathub for malware that impersonates a well-known application from GNOME, KDE, Mozilla, Signal, and so on. It does not entirely block a would-be malware publisher from playing a long game and trying to sneak malware in under a unique application name, but Flathub does put up a few hurdles to that approach as well.
First, Flathub verification requires a one-time manual approval by one of the Flathub administrators when an application is first uploaded. Hubert Figuière, one of Flathub's administrators, said via chat that some applications are abandoned during the verification process and that requests are closed after a year of inactivity. Secondly, Flathub applications are usually (with some exceptions like Mozilla) not uploaded directly to Flathub. Source is submitted to Flathub with a manifest, and the application is built by Flathub. Users can build a Flatpak locally if they wish to verify that it matches the source code repository. In the case of proprietary applications, build logs are available via Flathub, but the binary source is not available.
Finally, Flathub's build validation checks for changes to an application's requested permissions or metadata. Flatpak applications are run in a sandbox that provides some isolation from other applications and restricts access to system resources. If an update changes the requested permissions, or tries to change the application's name, then it will be held for manual review and may be rejected.
A verified application will have a blue check mark on its page in the Software application in GNOME. By sticking to verified software, users should be less likely to install anything malicious on their system. GNOME 46 makes this even easier by adding an option to only display software from verified developers. The downside to this is that Software only displays applications available via Flathub—it doesn't even display software from Fedora's standard repositories as verified.
GNOME also nudges users toward placing more trust in Flatpaks in its Settings
application. In the Apps settings page, users can manage their
applications' sandbox permissions, such as whether an application can send
notifications or receive and send system search results. When looking at settings for
an application that is installed as an RPM, Settings shows a blue bar underneath the
window title that says "App is not sandboxed
", with a small info
button to the side.
If the user clicks this to learn more, then Settings helpfully informs them that application settings cannot be enforced for applications that are not sandboxed. It does not tell the user what sandboxing is, however, or if it is something the user can enable. A significant number of GNOME users will probably intuit that this means that the application is not installed as a Flatpak, but many others are likely to be confused. A pointer to better documentation, and perhaps a recommendation for an equivalent Flatpak, would be an improvement here. Well, it would be an improvement if one considers Flatpak a better application-packaging method than RPMs or Debian packages.
Flatpak, as a format, has some interesting features and provides convenience. But one of its trade-offs is that an application does not go through the rigorous packaging process that an application must go through to be in a Linux distribution's repository. In short, many Linux users have come to trust that software in their favorite distribution's repository has been fully vetted. Removing the distribution vendor or project from that process may be more expedient, but it has a number of downsides in terms of actual verification and examination of software.
Libadwaita 1.5
Another change in GNOME 46 is the update to Libadwaita 1.5. Adwaita is GNOME's "design language", and Libadwaita is the GTK 4 library that implements GNOME's human interface guidelines (HIG). Libadwaita is the library developers want if they are trying to develop an application that looks and feels like part of GNOME.
The big change in 1.5 is adaptive dialogs, which are dialogs that are attached to an application's main window. When a user opens the preferences for their GNOME application that uses Libadwaita 1.5, that dialog won't be a separate window.
GNOME developer Alice Mikhaylenko wrote about the rationale for the change in detail, but the primary goal is to improve support for applications on mobile devices where a separate dialog box does not make sense. On the desktop, it is debatable whether this is an improvement or not. As implemented right now, the dialog doesn't show up when tabbing between windows or even on the thumbnail for a window. So if a user opens the preferences for Letterpress, switches to another window, it effectively disappears if the user is expecting to see it when switching applications. It would be interesting to see how it works on a GNOME mobile device, but there are few such systems readily available.
Getting closer
Users have been looking for Variable Refresh Rate (VRR) support from GNOME for some time, and the project accepted a freeze extension to get the work done in time to land in GNOME 46. In a nutshell, VRR allows a device to adjust its refresh rate to match the frame rate of the video source. This is a particularly interesting feature for gaming, since the frames per second can fluctuate wildly while playing.
VRR support has required a great deal of work and testing over the years, not just in GNOME but also in Wayland. The good news is that it is now available in GNOME 46. The bad news is that it is an experimental feature at present, which means that users should temper expectations when trying it out. VRR can be toggled on with a gsettings command to enable the option to turn on VRR in settings:
$ gsettings set org.gnome.mutter experimental-features "['variable-refresh-rate']"
I say "should" because VRR is not available with any combination of hardware that I've tried, including a gaming monitor that supports AMD FreeSync. Now that the VRR support is more widely available, though, it gives me hope that things will work in the not-so-distant future.
Extensions
The Extensions application has been retooled in this release as well. It features an upgrade assistant that checks compatibility with recent versions of GNOME to see if installed extensions are compatible with a newer (or older) release. This is useful to run before upgrading, and a little depressing to run afterward. One of the downsides to a new GNOME release is finding, once again, that some (or many) extensions don't work with the new release yet. In this case, six of the ten extensions on my system were unsupported, though one (ddterm) had an update available. Dash to Dock, Tray Icons Reloaded, WinTile, gTile, and Background Logo were all listed as unsupported.
This is such a common problem that the project has a page in the Guide to JavaScript for GNOME. The page explains why extensions break or stop working, why GNOME resumed version validation with GNOME 40, and how developers can avoid breakage by sticking to approved APIs or writing an application instead of an extension.
It is not hard to understand why the project would prefer that users and developers stick to the straight and narrow path of approved ways to extend and work with the desktop. And yet, users and developers keep trying to adapt GNOME to their needs and continue to find it frustrating. For many users, GNOME is almost perfect for their needs, with one or two exceptions. Extensions are often the only way to close the gap between almost perfect and perfect; or, at least, as close to perfect as one might manage with a desktop. Perhaps one day, GNOME and extension developers will manage to meet in the middle so that users can run the latest GNOME release and enjoy their favorite extensions too.
Overall, GNOME 46 is a solid release with quite a few improvements, and it's likely to be a little bit nicer by the time it lands in stable Linux releases. The upcoming Fedora 40 and Ubuntu 24.04 releases will have GNOME 46 by default, and it is already in Arch Linux and openSUSE Tumbleweed repositories.
High-performance computing with Ubuntu
Jason Nucciarone and Felipe Reyes gave back-to-back talks about high-performance computing (HPC) using Ubuntu at SCALE this year. Nucciarone talked about ongoing work packaging Open OnDemand — a web-based HPC cluster interface — to make high-performance-computing clusters more user friendly. Reyes presented on using OpenStack — a cloud-computing platform — to pass the performance benefits of one's hardware through to virtual machines (VMs) running on a cluster.
Open OnDemand
High-performance computing is, according to Nucciarone's slides: "A paradigm where you use supercomputers, computing clusters and grids to solve advanced scientific challenges." Nucciarone — a self-described "not so ancient elder of Ubuntu HPC" — has been involved with Ubuntu's HPC community team since it formed in the wake of the 2022 Ubuntu summit. At that event, participants from Canonical and Omnivector noticed that they were facing a lot of the same problems trying to package software for use on HPC clusters, and formed the community team to try and address that. Nucciarone called for people to join the group if they think it's interesting, even if they are not currently doing any HPC work.
![[Jason Nucciarone]](https://static.lwn.net/images/2024/Jason_Nucciarone-small.png "Jason Nucciarone")
He moved on to the main focus of the talk by asking why, even though HPC users are "bright and smart people", they often have trouble taking full advantage of an HPC cluster. He gave some examples of commonly touted reasons, such as the fact that HPC clusters often use different tech stacks, or that the system is "too advanced". None of those are the main problem he sees. "The main problem is this: the terminal."
HPC clusters are often organized with a pool of worker nodes where jobs are sent. Users do not connect to workers directly, but rather to a "head node" or "jump host" that provides them with tools to manage the cluster. When a new HPC user connects (invariably via SSH) to the head node of a cluster, they are presented with a shell prompt. Nucciarone pointed out four problems with this: affordances, learnability, consistency, and visibility. Firstly, the terminal doesn't tell the user what it can do. This makes discovering what the system is capable of difficult. Secondly, the languages involved in running an HPC system all have their own learning curve. Becoming simultaneously proficient in bash, Python, and any other programming languages in use on the cluster is a tall order. Thirdly, each tool has its own interface and command-line conventions. Learning the interface of one tool does not guarantee a user can transfer that knowledge to another tool. Finally, the shell just provides a user with a blank prompt, it doesn't guide them toward what to do next. "How do you learn what you don't know if you don't know what you don't know?"
Nucciarone's proposed solution to this is Open OnDemand, "an interactive portal for accessing HPC resources over the internet". He also described it as a "web-based application that moves beyond the terminal" and that "focuses on providing a visual interface for accessing your HPC resources". The benefits of using Open OnDemand include the ability to use interactive applications like notebooks, compatibility with many existing cluster scheduling systems, and even the capacity to "launch a desktop session directly on your cluster" (enabling users to run graphical applications on the cluster), he said.
The Ubuntu HPC team has been working to develop "Charmed HPC", a system to make deploying HPC clusters from scratch much easier using Juju. Open OnDemand could tie into that by providing a better user interface for users out of the box. For that to work, though, Open OnDemand needs to be packaged for Ubuntu, which is what Nucciarone is currently working on.
He has been writing a snap that runs all the services required for Open OnDemand. He gave a demo showing how this makes spinning up the Open OnDemand web interface as simple as installing the snap and then starting the service. Actually using the web interface for anything requires having a correctly configured HPC cluster already set up to connect to, of course.
Nucciarone is currently working on OpenID Connect integration and sorting out some internal problems with Open OnDemand. One particular difficulty has been packaging the custom versions of the Apache and NGINX web servers that Open OnDemand requires. When asked why both were needed simultaneously, Nucciarone replied: "To be honest, it's not quite clear to me myself". He went on to say that that was how the upstream project had it, and that a lot of their tooling is built around using Apache.
Once his work on fixing the last few problems is finished, he plans to make the snap available in the Snap Store. In the future, he wants to add built-in support for a base set of interactive web applications, and write a Juju operator for easy deployment. Nucciarone ended his talk by once again asking people to join the Ubuntu HPC team.
OpenStack
Reyes's talk was aimed at a slightly different audience. He talked about how to use OpenStack — an infrastructure-as-a-service platform which can be used to configure HPC clusters — to get the most performance out of a cluster. OpenStack allows users to run virtual machines on a cluster, transparently handling the setup of networking, migration of workloads, etc.
![[Felipe Reyes]](https://static.lwn.net/images/2024/Felipe_Reyes-small.png "Felipe Reyes")
He described the relevant components of an OpenStack cluster, and pointed out that everyone has different metrics that they care about optimizing. Different people will care about throughput, CPU usage, latency, etc. He also showed a diagram from Brendan Gregg of the myriad performance-observation tools that we have to keep track of these things.
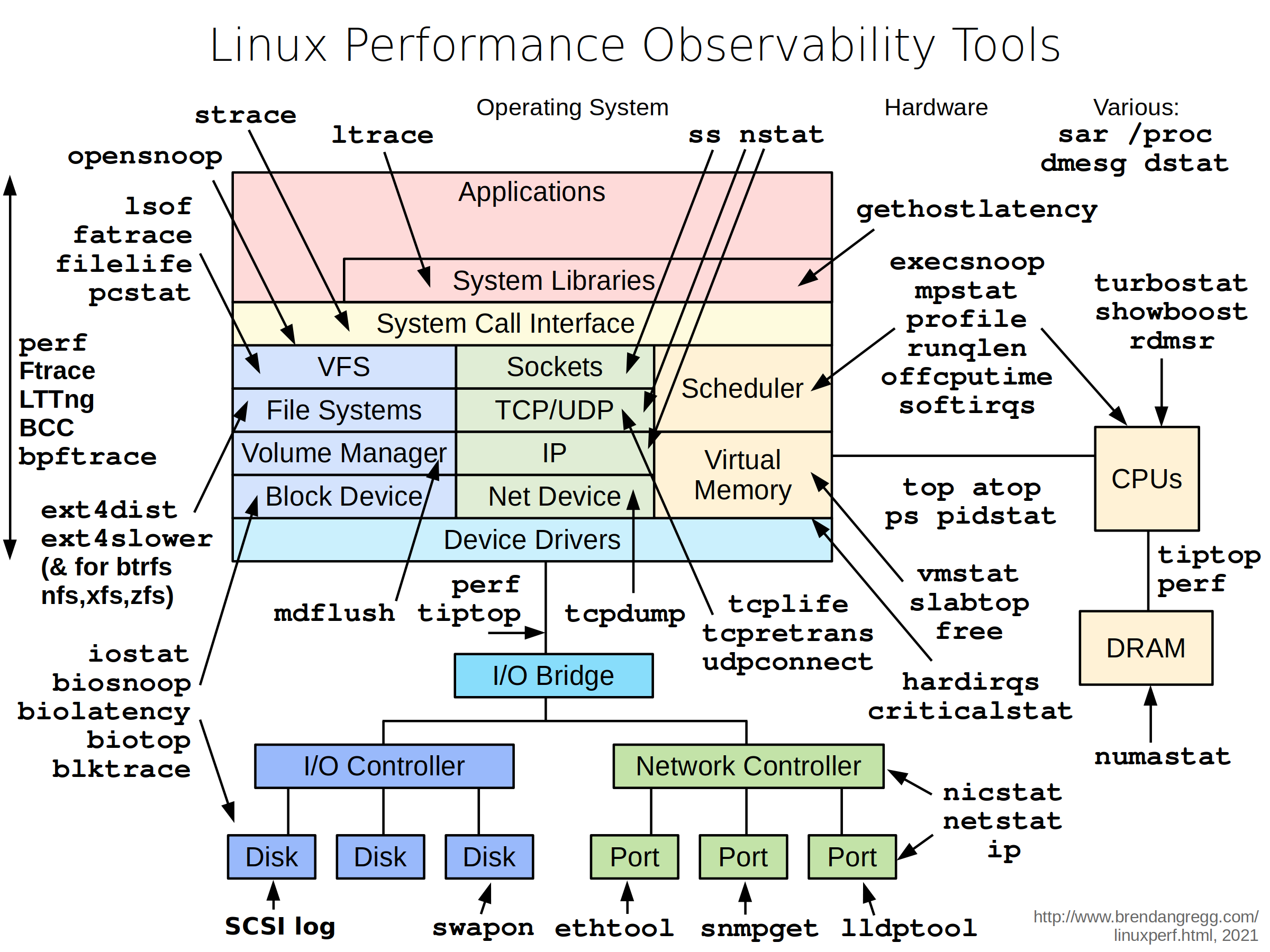{kind=link}
There are a number of different configuration options that users of OpenStack have available to fine-tune the performance of their clusters. Reyes explained how one can create "flavors" — particular types of node available on a cluster, fine-tuned to a particular workload. "You may have a fleet of nodes, and those nodes may have different properties", he explained. Segmenting nodes with a particular property (for example, solid-state drives) into a separate flavor can help the scheduler to decide where a VM running on the cluster ought to be assigned.
Once nodes have been split into flavors, the rest of the settings he discussed can then be applied per-flavor. The general theme of the options is making the virtualized hardware that is available to the VM map as closely as possible to the underlying physical hardware, to avoid overhead. Reyes summed this up as trying to get a "good representation so the hardware can be taken advantage of".
In pursuit of this, flavors can specify the number of sockets, cores, and threads made available for each VM. Those virtual CPUs can then be pinned, to ensure that specific physical CPUs are used for each virtual CPU. If no other VMs have access to those CPUs, this will ensure that only the configured VMs can run there. This isn't sufficient to give full control of the CPUs to the VM, though. The host kernel could still choose to run kernel tasks on those CPUs. To solve this, Reyes recommended adding the isolcpus command line option, to instruct the Linux kernel not to schedule tasks on those CPUs. "This gives you the guarantee that any VMs [...] are not competing for resources."
He also noted that OpenStack supported configuring Non-Uniform Memory Access (NUMA) for each flavor. Usually, the kernel picks up information about the NUMA configuration of a machine from the hardware. By configuring the virtual hardware of the VM to match the real NUMA properties of one's cluster, one can let the kernel take advantage of its NUMA optimizations. By default, VMs have only one NUMA node, but one can configure a more-specific setup, including the ability to "create asymmetric definitions".
During the Q&A session, Nucciarone asked what could be done to improve the documentation of these options, so that people running private clusters know what they need to do. Reyes responded that the documentation was indeed a problem, and "makes a lot of assumptions", ultimately suggesting that it could be improved by adding more pointers to other places where people can learn about concepts like NUMA.
Another member of the audience asked whether the documentation should include example use cases. Reyes agreed with the spirit of the request, but said that it was tricky because people sometimes take examples in documentation as golden rules that they can copy and paste without understanding. "If you don't understand the characteristics of the things you're running, it's better to stay in the defaults". This led to some discussion, with a different member of the audience saying: "No default works well for everyone".
Ultimately, the configurations Reyes discussed are highly specialized, and probably best employed by people who already know how details like NUMA and CPU-pinning work. He was clear that while these options offered fine control over the performance characteristics of hosted VMs, there is no substitute for actually measuring the performance characteristics one is interested in improving.
Conclusion
High-performance computing is a challenging industry. Despite that, people are putting significant effort into making Ubuntu more useful as a platform for building an HPC cluster. Future developments are likely to be reported on Ubuntu's HPC Blog or discussed on the Ubuntu Discourse forum.
[I would like to thank LWN's travel sponsor, the Linux Foundation, for travel assistance to Pasadena for SCALE.]
Hardening the kernel against heap-spraying attacks
While a programming error in the kernel may be subject to direct exploitation, usually a more roundabout approach is required to take advantage of a security bug. One popular approach for those wishing to take advantage of vulnerabilities is heap spraying, and it has often been employed to compromise the kernel. In the future, though, heap-spraying attacks may be a bit harder to pull off, thanks to the "dedicated bucket allocator" proposed by Kees Cook.Consider, for example, a use-after-free bug of the type that is, unfortunately, common in programs written in languages like C. Memory that is freed can be allocated to another user and overwritten; at that point, the code that freed the memory prematurely is likely to find an unpleasant surprise. The surprise will become even less endearing, though, if an attacker is able to control the data that is written into the freed memory. Often, that is all that is needed to turn a use-after-free bug into a full kernel compromise.
It is, of course, difficult for an attacker to get their hands on precisely the chunk of memory that is being mishandled in the kernel. When precision is not possible, sometimes brute force will do. Heap spraying involves allocating as many chunks of memory as possible, and writing the crafted data into each, in the hope of happening upon the right one. Given the way that the kernel's slab allocator works, the chances of succeeding are higher than one might expect.
The kernel has a variety of ways to allocate memory but, much of the time, a simple call to kmalloc() is used; this is especially true if the size of the memory to be allocated is not known ahead of time. Within the allocator, the requested memory size is rounded up to the nearest "bucket" size, and the requested chunk is allocated from the associated bucket. Those sizes are (mostly, but not exclusively) powers of two, so any allocation request between 33 and 64 bytes, for example, will be satisfied from the 64-byte bucket.
If an attacker has determined that a given structure, allocated with kmalloc(), is used after being freed, they can attempt a heap-spraying attack by forcing the kernel to allocate (and write) a large number of objects from the same bucket. As it turns out, there are ways in which an attacker can get the kernel to do just that.
The solution to this kind of problem (beyond fixing every use-after-free bug, of course) is to keep the allocation pools separate. If every allocation comes from its own heap, it cannot be used to spray somebody else's heap. Unfortunately, the current design exists for a reason; using common buckets for allocations across the kernel significantly increases allocation efficiency and memory utilization. So that is unlikely to change.
During the 6.6 development cycle, an effort to improve the kernel's resistance to heap spraying, in the form of the kmalloc() randomness patches, was merged. This work split each of the kmalloc() buckets 16 ways and caused the allocator to pick a random bucket (based on the request call site) to satisfy each request, with the result that a heap-spraying attack has a high chance of hitting the wrong bucket. It is a way of partially separating allocations without giving up entirely on a common set of heaps. Randomness hardens the kernel to an extent, but it is a probabilistic defense that will surely fail at times.
The key point behind Cook's approach is that it is not necessary to separate all allocations into their own heaps; if the kernel could ensure that any user-controllable allocation is satisfied from a different pool than anything else, heap spraying would be much harder to implement. To get there, a new API must be created for kernel subsystems that perform user-controllable allocations; that is what the patch series does.
The first step for such a subsystem is to create its own heap for variable-size allocations with a call to:
kmem_buckets *kmem_buckets_create(const char *name, unsigned int align,
slab_flags_t flags,
unsigned int useroffset,
unsigned int usersize,
void (*ctor)(void *));
This call is similar to kmem_cache_create(), which creates a heap for fixed-size allocations. The name of the heap (which can be used for debugging) is given by name, and align describes the required alignment for objects allocated there. Flags for the slab allocator are given in flags. The useroffset and usersize parameters describe the portion of an object that might be copied to or from user space (information that is used by the kernel's user-space copying hardening mechanism), and ctor() is an optional constructor for allocated objects. The return value is a pointer to a kmem_buckets object that can be used for future allocations.
Once that call succeeds, objects can be allocated with:
void *kmem_buckets_alloc(kmem_buckets *b, size_t size, gfp_t flags);
Here, b is the pointer returned by kmem_buckets_create(), size is the size of the allocation, and flags is the usual GFP flags; a pointer to the allocated memory is returned. A normal kfree() call can be used to free objects when they are (truly) no longer needed. There is also a kmem_buckets_valloc() that can fall back to vmalloc() if need be.
The other part of the puzzle is to use this new allocator in the right places. Seemingly, the msgsnd() system call is a favorite tool for heap-spraying attacks, since the kernel implements it by allocating a structure to contain the message to be sent (the size and contents of which are controlled by user space). Cook's series includes a patch causing msgsnd() to use the new bucket allocator, separating its allocations from all others and removing its utility in this kind of attack. Another patch switches the internal memdup_user() and vmemdup_user() functions, which are used to copy data from user space into the kernel. Many of the call sites for those functions will give user space some control over allocation sizes, so isolating them could prevent a lot of problems.
While the proposed changes are relatively small, they could have an oversized impact on kernel security. Separating off user-controllable allocations in this way can block many of the exploits that have succeeded against the kernel in the past. Creating a kernel that is free of memory-safety bugs does not seem like a feasible goal in the near future, but making one where such bugs are harder to exploit is possible. Chances are that this patch series, in some form, will show up in the mainline before too long.
The rest of the 6.9 merge window
The 6.9-rc1 kernel prepatch was released on March 24, closing the merge window for this development cycle. By that time, 12,435 non-merge changesets had been merged into the mainline, making for a less-busy merge window than the last couple of kernel releases (but similar to the 12,492 seen for 6.5). Well over 7,000 of those changes were merged after the first-half merge-window summary was written, meaning that the latter part of the merge window brought many more interesting changes.The most significant work merged in the second half of the 6.9 merge window include:
Architecture-specific
- The Rust language is now supported on 64-bit Arm processors.
- It is now possible to run 64-bit Arm CPUs in LPA2 mode, which sets up a 52-bit virtual address space.
- The LoongArch architecture has gained support for the ORC stack unwinder, the objtool binary tool, and kernel live patching.
- RISC-V systems now support the membarrier() system call.
Core kernel
- Weighted interleaving has been merged, providing better control over how pages are placed on heterogeneous-memory systems.
- Basic continuous-PTE support has been added for 64-bit Arm processors. This feature, described in this article, improves performance by enabling better translation lookaside buffer (TLB) usage.
- Memory-management performance has also been improved with the merging of a patch series reducing vmalloc() lock contention.
- Function return probes can now access the arguments that the probed function was called with; this feature can help to spot changes made to those arguments. This changelog includes a usage example.
Filesystems and block I/O
- The device mapper "virtual data optimizer" (VDO) target has been
added.
The dm-vdo (virtual data optimizer) target provides inline deduplication, compression, zero-block elimination, and thin provisioning. A dm-vdo target can be backed by up to 256TB of storage, and can present a logical size of up to 4PB. This target was originally developed at Permabit Technology Corp. starting in 2009. It was first released in 2013 and has been used in production environments ever since. It was made open-source in 2017 after Permabit was acquired by Red Hat.
See this documentation commit for design and usage information.
- The work to add online filesystem checking and repair to XFS continues, with another set of data structures now covered.
- The ext2 filesystem has been marked as deprecated, mostly as a result of its inability to properly represent dates after January 2038. The filesystem is not going anywhere anytime soon, and ext2 filesystems are also covered by the ext4 module, but users are being encouraged to avoid it.
- Initial support for FUSE passthrough has been merged. This feature allows I/O to files served by a user-space FUSE server to be handled directly by the kernel, without the need to involve that server. The result can be a significant performance increase in some cases. For 6.9, passthrough mode only supports privileged servers; expanding availability is a task for a future release.
Hardware support
- Clock: R-Car V4M clocks, Qualcomm X1E80100 clock controllers, and Qualcomm SC7180 modem clock controllers.
- GPIO and pin control: R-Car V4M (R8A779H0) pin controllers and Awinic AW9523/AW9523B I2C GPIO expanders.
- Graphics: Boe TH101MB31UIG002-28A panels, Novatek NT36672E DSI panels, Freescale i.MX8MP HDMI PVI bridges, Freescale i.MX8MP HDMI-TX bridges, Himax HX83112A-based DSI panels, and Renesas RZ/G2L display units.
- Hardware monitoring: Analog Devices LTC4282 high-current hot-swap controller I2C interfaces, Microsoft Surface Pro 9 fan monitors, Monolithic Power MPQ8785 step-down controllers, Amphenol ChipCap 2 relative humidity and temperature sensors, NZXT Kraken X53/X63/X73 and Z53/Z63/Z73 coolers, ASUS ROG RYUJIN II 360 fan/sensor controllers, Astera Labs PT5161L PCIe retimer temperature sensors, and ASPEED g6 PWM and Fan tach controllers.
- Industrial I/O: AMS AS7331 UV sensors, Analog Devices ADMFM2000 dual microwave down converters, Texas Instruments ADS1298 medical analog-to-digital converters, Microchip Technology PAC1934 power monitors, and Voltafield AF8133J 3-Axis magnetometers.
- Input: Goodix Berlin touchscreens.
- Miscellaneous: ChromeOS EC GPIO controllers, Maxim MAX6958/6959 7-segment LED controllers, Kinetic KTD2801 1-wire GPIO-controlled backlights, ON semiconductor NCP5623 LED controllers, MediaTek MIPI CSI CD-PHYs, Rockchip Samsung HDMI/eDP Combo PHYs, and Qualcomm MSM8909 and SM7150 interconnects.
- Sound: Qualcomm WCD9390/WCD9395 codecs and generic framer-based codecs.
- USB: ITE IT5205 Type-C USB Alt Mode Passive multiplexers and Realtek RTD USB2 and USB3 PHY transceivers.
Miscellaneous
- See this merge message for a summary of new features added to the perf tool for 6.9.
- User events in the tracing subsystem can now export multiple formats; this is useful, for example, if a library's format changes. This documentation commit contains a little more information; see also the series cover letter.
Security-related
- The kernel's Integrity Measurement Architecture and Extended Verification module (IMA/EVM) have been converted into proper Linux security modules. There should be no user-visible effects, but this change, which was enabled by the slowly proceeding security-module stacking work, simplifies the code considerably.
- The API for the security-module system calls merged in 6.8 has changed for better 32-bit compatibility. In theory, this change could break applications, but these system calls have only been in a released kernel for a few weeks, so the chances are that they are not yet being used. Linus Torvalds agreed that this change was probably safe to make.
Internal kernel changes
- The kernel's energy model can now be updated at run time; this allows the kernel to, for example, take into account the effect of operating temperature on a CPU's energy efficiency.
- The minimum version of LLVM that can be used to build the kernel is now 13.0.1.
- The S/390 architecture has long used kernel virtual addresses that are the same as the underlying physical addresses, leading to a certain amount of sloppiness in distinguishing between the two address spaces. There is currently a plan to separate the kernel's address space, meaning that said sloppiness needs to be cleaned up. Some new types have been introduced to mark physical addresses, allowing the sparse tool to find code that uses the wrong address type.
Better luck next time
- The Arm "WXN" mode was briefly supported. When enabled, WXN disables, at the hardware level, the ability to have memory that is both writable and executable. The kernel is able to run under this mode; whether all user-space workloads can is less certain, so it is not clear whether distributions will enable WXN by default. The arm64.nowxn command-line option can be used to disable WXN at boot time if need be. Unfortunately, some problems resulted and WXN support was reverted for now.
- An attempt was made to remove the ability to collect and report statistics from the crypto layer. This commit contains the reasoning behind this removal; in short, the feature was never documented, seemingly never used, and slows down cryptographic operations. The change ended up being reverted for now — it turned out to also remove some useful functionality — but seems sure to return in a future development cycle.
The stabilization of all this work can be expected to take until May 12 or 19, at which point the final 6.9 kernel will be released. The earlier date would put the first half of the merge window right on top of the Linux Storage, Filesystem, Memory-Management, and BPF Summit, which seems likely to create a certain amount of maintainer stress. Between now and then, though, there will be a lot of bugs to fix and rough edges to smooth; the kernel development community will be busy, as usual.
Nix at SCALE
The first-ever NixCon in North America was co-located with SCALE this year. The event drew a mix of experienced Nix users and people new to the project. I attended talks that covered using Nix to build Docker images, upcoming changes to how NixOS performs early booting, and ideas for making the set of services provided in nixpkgs more useful for self hosting. (LWN covered the relationship between Nix, NixOS, and nixpkgs in a recent article.) Near the end of the conference, a collection of Nix contributors gave a "State of the Union" about the growth of the project and highlighting areas of concern.
Docker
Xe Iaso, a "Senior Technophilosopher" at Fly.io gave a talk called "Nix is a better Docker image builder than Docker's image builder". Iaso opened the talk by explaining that "Nix is different from what many developers expect", and requires "a lot of work upfront". Because of that, xe (Iaso uses xe/xer pronouns) is worried that "Nix will wither and die in the industry". Xe said that Docker, on the other hand, has had unparalleled success. It has become the "de-facto package format for the internet", with many large hosting providers (such as Iaso's own employer) offering the ability to run Docker containers as a service. Xe proposed that showing how Nix could fit into existing workflows that use Docker — while delivering better reproducibility and performance — could help drive Nix adoption.
![[Xe Iaso]](https://static.lwn.net/images/2024/Xe_Iaso-cropped.png "Xe Iaso")
Iaso said that despite its widespread use and adoption, Docker has a fatal flaw: "Docker builds are not deterministic, like not even slightly". Docker image builds frequently have access to the internet, which is needed to download packages for inclusion in the image. Unfortunately, recreating the exact set of inputs to a build is hard, because servers on the internet change all the time, making recreating an image later difficult.
This also has the effect of ensuring that some common software artifacts — such as the GNU C library (glibc) — are duplicated many times across different containers. While it is possible to split glibc into its own Docker "layer" that can be reused between Docker images when it has not changed, most Docker images don't do this. Instead, it is common to first update local package lists through the equivalent of apt update, and then install software directly into another layer. This means that every time the Docker image is rebuilt, the first layer where the package lists are fetched changes, which invalidates the second layer and requires re-downloading and storing another copy of the software that the image uses.
Iaso asked the audience to imagine: "What if your builds didn't need an internet connection, because everything was already downloaded and in the path for you before your build started?" This can be done using Nix, because "Nix lets you know exactly what you depend on ahead of time". Xe then went on to show a demo of a simple Go application, and the steps required to package it in a Docker image using Nix.
nixpkgs has a library called dockerTools — a set of tools to put packages into Docker images in "opinionated ways". Building an image with dockerTools requires little configuration if the project being built is already specified with Nix. The Docker images built in this way do not depend on Nix once built, and can be used like any other image. The library can build Docker images as a single layer, but the preferred method is to put each package in its own layer, which allows sharing layers not only between subsequent builds of the same software, but also between images for different services that have some overlap in their dependencies. Glibc, for example, is a dependency of nearly everything. Putting it in a separate layer allows every Docker image built in this way that depends on that specific version of glibc to share the relevant layer. Sharing layers doesn't just reduce storage costs, it also reduces build times, because Nix can cache image layers the same way it caches other build outputs. "It's magic; it's saved me so much time".
During Q&A, a member of the audience asked if there is "a practical limit to the number of layers". Iaso responded: "Yes, and that limit is 128, and it's dictated by the filesystem drivers that Docker uses." Xe went on to specify that if there are more Nix packages than available Docker layers, the dockerTools library will make the least popular (and therefore least likely to be shared) packages share a layer. Another person asked "What about layer ordering?", referring to the way that a Docker container contains layers in a specific order. Iaso explained that layer ordering is "an illusion" that doesn't actually impact the functionality of the image (unless one layer overwrites a file provided by another layer), and that Nix picks an arbitrary order.
Systemd
Will Fancher gave a talk about the multi-year effort to upgrade NixOS's init system. When a Linux system boots, the bootloader loads a kernel and an initial RAM disk. The kernel unpacks the RAM disk and launches an init process as PID 1 from it. It is PID 1's job to actually set up the system to run by attaching the correct disks, filesystems, loading required kernel modules, and anything else necessary to setting up the fully booted system.
![[Will Fancher]](https://static.lwn.net/images/2024/Will_Fancher-cropped.png "Will Fancher")
In NixOS, this step is currently done by this shell script that Fancher referred to as "scripted stage one", which encapsulates "the sequence of steps that needs to be taken by just about any installation of NixOS". The problem with this script is that it's serial and imperative. "It's all written in this ... shell-scripty kind of way. [...] It's all a little co-dependent. It's awkward to maintain, and it's frustrating to write." It's also "a lot of custom code" that NixOS can't really directly share with other projects.
Since 2022, Fancher has worked with other members of the Nix community on an alternative. Systemd is already used as PID 1 on a fully booted NixOS system; this new work also makes it part of the initial RAM disk used to set up the system. Using systemd from the beginning has several advantages, including that systemd is declarative, parallel, and that it provides "tools that come straight out of the systemd project, that we don't have to develop and maintain ourselves". These tools include niceties such as rescue and debug shells, systemd-networkd for configuring networking in a more robust way, systemd-ask-password to unify the interface for letting services request passwords on boot, and systemd-cryptsetup for supporting hardware keys for disk encryption.
Fancher gave an example from his own work where a server had a complicated tangle of different encrypted disks and networking services that were required to boot properly. He said that systemd lets you specify these kinds of complicated setups in an elegant way. He also pointed out that systemd's parallelism might speed up the early boot by preparing multiple disks simultaneously, although since this phase of the boot process is "only a few seconds for most systems", the impact won't be large.
The work to bring systemd to NixOS's early boot is quite far along. The option to enable the new mode was stabilized toward the end of last year in version 23.11, and Fancher hopes for it to become the default in version 24.05, which is expected in May. He said that there were still minor incompatibilities, but that those are detected at build time and a warning is issued while falling back to the existing code. He called out bcachefs, in particular, as something that does not yet work with the new setup, saying: "The reason it works in scripted stage one at all right now is basically luck." NixOS users wishing to try the new stage one implementation early can set boot.initrd.systemd.enable in their configurations.
Once the new mode becomes the default, version 24.11 (expected in November) will remove the networking code in the existing scripted stage one, which Fancher called out as particularly "janky". Assuming this goes as planned, version 25.05 will remove scripted stage one entirely. At the end of his talk, Fancher said that the work had involved a lot of collaboration, and said that a takeaway should be: "If there's a little thing that you want to contribute, then you should go ahead and contribute."
Module contracts
Pierre Penninckx gave a more theoretical talk calling for the Nix community to standardize a set of conventions for configuring services. Standing up a service that has been packaged for NixOS is easy; Penninckx showed how to run Nextcloud on a NixOS server:
services.nextcloud.enable = true;
"Since the moment I saw that, I thought 'I need to use Nix for everything now'."
This ease comes at a cost, however. All of the other services that a particular service depends on are hard-coded by the maintainer of the NixOS module. For example, Nextcloud depends on NGINX, PostgreSQL, and a handful of other services. A user wishing to substitute Apache as the reverse proxy in front of Nextcloud would be out of luck unless they forked the NixOS module and wrote their own definition. This also means that there's no good way to reuse the configuration of smaller components between different modules.
![[Pierre Penninckx]](https://static.lwn.net/images/2024/Pierre_Penninckx-cropped.png "Pierre Penninckx")
To remedy this, Penninckx suggested having explicit contracts between modules. NixOS modules communicate with each other via configuration options in a central attribute set (Nix's equivalent of a dictionary). Explicit contracts between modules would be sets of configuration options that all the modules of a given type would agree to support — both for receiving and setting.
For example, two different database systems would support the same set of options for specifying that a service needs its own database user, and would produce the same set of options describing how to connect to the database in response. Each system could still have its own extra configuration options to cover things unique to that system, but they would support a common core of operations. This would make it easy to swap out two different equivalent services, giving more choice to the end user. "That's to me very powerful".
Penninckx pointed out that there are already a lot of implicit contracts between modules. For example, almost every service in NixOS supports a boolean enable option, to the point where users often don't even need to check the docs to know that the option will exist. Everybody expects enable to work in the same way between services, even though that's just an undocumented convention. There are several examples of patterns like that in nixpkgs that he pointed out.
Penninckx called on the community to spend some time planning how to formalize these contracts. He recognized that would take work, but thought that the effort would be worth it, and pointed out that the Nix community has a track record of pulling off long-term plans, such as the stage one changes from Fancher's previous talk. During Q&A, one member of the audience pointed out that the Kubernetes project already has a similar kind of abstraction, and suggested that perhaps the Nix project could coopt some of that design. Penninckx responded that "Yes, we could probably learn a trick or two from there".
The working examples that Penninckx has put together for his own use live in the Self Host Blocks project, which includes examples of how to set up contracts with automatic integration tests to make sure that the options have consistent effects across different services of the same type. It also includes "building blocks" for the services he uses — a collection he hopes to expand over time. He invited people who were interested in the topic to join the Matrix channel dedicated to the project to discuss what the next steps are.
State of the union
Toward the end of NixCon, a chaotic mix of presenters including Eelco Dolstra, original creator of Nix, and Ron Efroni, CEO of Flox and longtime Nix contributor, gave a Nix "State of the Union" talk for 2024. They went into how the Nix project has grown, what challenges the project is currently facing, and what people can do to contribute.
The general outlook was positive, with the community growing in every metric, including contributors, donations, and active users. However, there is one source of concern, which is whether Nix's funding can keep up. "This technology is not yet fully self-sustaining", Efroni warned. Much of Nix's funding comes from NLnet, but large amounts of support are also provided by various companies and individual donations.
LogicBlox, which is no longer an independent company, had provided support for NixOS since 2010 in the form of paying for the storage costs of NixOS's build-cache infrastructure. That cache has grown to 399.3TB of infrequently accessed data, and 111.5TB of recently accessed data comprising 793 million objects. In 2023, LogicBlox decided that it was unable to keep up with the growing demands of the cache, and that it could no longer continue its sponsorship. The Nix community pulled together and found alternative funding sources over the course of two weeks, but the incident was something of a wakeup call for the Nix foundation that Nix needs additional funding to be sustainable in the long term. "The goal of the foundation is to create a Nix that is sustainable," Efroni explained.
Dolstra took over the presentation at that point to explain the technical measures that the project plans to take to reduce the costs of the cache, including garbage collecting build artifacts of releases made more than two years ago. "The cache cannot keep growing forever, probably".
He clarified that they would keep the final version of each release, to make checking out historical versions of nixpkgs easier. He also stated that they would not be removing cached source code, so that rebuilding old versions of packages would remain possible. "The sources will still be there", Dolstra promised.
Finally, a succession of contributors took the stage to talk about all the different teams within the Nix project that are necessary to make it a success, including build infrastructure, architecture, moderation, marketing, and more. They all encouraged people to get involved by joining the Nix Discourse and Matrix space.
Overall, NixCon ran smoothly and drew dozens of people excited about the future of the project. The talks are currently available in the form of two recorded SCALE livestreams (stream 1, stream 2), but the SCALE YouTube channel will eventually have all the talks separated out and posted individually.
[I would like to thank LWN's travel sponsor, the Linux Foundation, for travel assistance to Pasadena for SCALE.]
Page editor: Daroc Alden
Inside this week's LWN.net Weekly Edition
- Briefs: Emacs 29.3; Linux 6.9-rc1; Nova for NVIDIA devices; Redis license; Rust 1.77; Simon Riggs RIP; Quotes; ...
- Announcements: Newsletters, conferences, security updates, patches, and more.