
LWN.net Weekly Edition for May 2, 2024
Welcome to the LWN.net Weekly Edition for May 2, 2024
This edition contains the following feature content:
- A look at Ubuntu Desktop LTS 24.04: the new long-term release of the Ubuntu distribution brings some nice features but also a few rough edges.
- A leadership crisis in the Nix community: unhappiness over the Nix project's direction boils over.
- Security patterns and anti-patterns in embedded development: an Open Source Summit session on how to create more-secure embedded systems.
- The state of realtime and embedded Linux: two sessions on where realtime and embedded Linux stand and what needs to be done next.
- Support for the TSO memory model on Arm CPUs: a disagreement over whether the kernel should expose a feature of some Arm processors.
- Giving Rust a chance for in-kernel codecs: how Rust can improve media-driver security with minimal disruption.
- Python JIT stabilization: the Python project approaches the conclusion of the just-in-time compiler effort.
This week's edition also includes these inner pages:
- Brief items: Brief news items from throughout the community.
- Announcements: Newsletters, conferences, security updates, patches, and more.
Please enjoy this week's edition, and, as always, thank you for supporting LWN.net.
A look at Ubuntu Desktop LTS 24.04
Ubuntu 24.04 LTS, code-named "Noble Numbat", was released on April 25. This release includes GNOME 46, installer updates, security enhancements, a lot of updated packages, and a new App Center that puts a heavy emphasis on using Snaps to install software. It is not an ambitious release, but it brings enough to the table that it's a worthwhile update.
Ubuntu users expecting to upgrade to the new release right away are in for a bit of disappointment. The release notes indicate that upgrades from earlier releases are not yet supported. Users on the previous release, 23.10, will be offered an upgrade via Ubuntu's software and updates application when it is ready. Moving from 22.04 LTS will be supported when 24.04.1 is released in August. Those eager to jump right in are advised to make a backup of their data and do a clean install rather than attempting an upgrade.
Meet the new LTS
Starting with a fresh install will provide a chance to try out the latest version of the Subiquity installer, which now includes the ability to update itself before beginning an installation. If the system is connected to the Internet, Subiquity will check to see if there is an update available and (if so) apply it before proceeding. This can be quite useful for addressing bugs or adding new features after the installation media for a release has been distributed.
One interesting change in the installer workflow is the addition of a step to set up accessibility features immediately after the language is selected. This may be a helpful addition for users who need assistive technologies, when it's fully ready. The screen reader included with the installer is described in the release notes as incomplete and has a number of bugs indicating that it is currently not usable to perform the installation.
The disk partitioning step now offers TPM-backed disk encryption if the system has a compatible trusted platform module (TPM). The ZFS filesystem is also offered as an option, as it is in the 22.04.4 LTS installer, but is now marked experimental and is lacking encryption support. The option to install ZFS was disabled in the 22.10 release due to a bug that caused problems on first boot. Support for guided ZFS installation was re-added in Ubuntu 23.10 with a note that encryption would return in a future release. Aside from those changes, the workflow for installation is basically the same as the previous LTS release.
Desktop
"Basically the same" is a theme that carries through to the desktop, at least at first glance. Once installed, there's little visible difference between 24.04 LTS and the prior LTS release. A few icons have changed, the wallpaper sports the Numbat logo, and the button that used to be labeled "Activities" in the top-left corner is replaced with a pill-shaped icon. Like its predecessor, clicking that will bring up the activities overview that shows all of the open application windows.
One of the user-interface improvements Ubuntu attempted to drive in previous releases was a "Global" menu that integrated the application's menu with the top bar of the desktop rather than in the application's window, in a similar fashion to the user interface of macOS. However, Apple is able to enforce uniformity in its interfaces in a way that Canonical cannot. It was an interesting idea that could have saved a bit of screen space, but most applications did not support the feature so the menu would only include a few menu options such as "quit" and "new window". It has been entirely removed in this release, which is understandable but unfortunate. No matter how much screen space is available, a little more is always appreciated.
The desktop is mostly standard GNOME 46, which we covered in March, with a few additions, tweaks, and the omission of the GNOME Software application along with support for Flatpaks. GNOME Software and Flatpak can be installed with APT, but only if users know to go looking for them.
The rest of the changes are minor in comparison. For example, in Ubuntu alt-tab cycles between windows rather than applications. The desktop sports the Ubuntu Dock, which is similar to the GNOME Dash-to-Dock extension except that it can't be disabled. There is also an "enhanced tiling" feature that provides more flexible window-tiling options than standard GNOME. Dragging a window to the corner of the screen will cause it to snap into position taking up either one-half or one-quarter of the screen. (GNOME only allows two windows to be "tiled" side-by-side.) It's still limited compared to extensions like gTile that allow a wide range of tiling options, but it can be useful.
![[Ubuntu Desktop]](https://static.lwn.net/images/2024/Ubuntu-Desktop-sm.png "Ubuntu Desktop")
Ubuntu Desktop now defaults to a "minimal" install that leaves out things like games, a mail client, and office software. This is an interesting evolution (no pun intended) from the early days of Ubuntu. When the distribution first arrived on the scene, one of its distinguishing characteristics was providing an opinionated selection of software rather than asking the user to choose from a dizzying array of options at install time. Now users are given a nearly blank slate. This does make some sense—in the nearly 20 years since the Warty Warthog release, people depend a lot less on locally installed software. A browser and a handful of applications may be all that a person needs to be productive if much of their software is browser-based. For additional software, users can turn to the new Ubuntu App Center.
![[Ubuntu App Center]](https://static.lwn.net/images/2024/App-Center-sm.png "Ubuntu App Center")
At first glance, it would be easy to conclude that the App Center only works with Snap packages. All of the software that users can find just by browsing the store is Snap-only. Debian packages are filtered out of searches. It would be unfair to say that the option of installing Debian packages is hidden, but it is easily missed.
Users who prefer to install software via the command-line will be mostly unaffected by the push toward Snaps. The exceptions include Firefox and Thunderbird, which are not available as standard Debian packages in the Ubuntu repositories. Instead, users who try to "apt install thunderbird" receive a dummy package that installs the Snap instead.
Of course, GNOME is not the only Ubuntu desktop flavor available. Users can opt for Budgie, Cinnamon, KDE, LXQT, Mate, or the Unity desktops. There are also use-case-specific options, Edubuntu for educational use, Kylin for Chinese users, and Studio for multimedia production.
Miscellaneous
Naturally, 24.04 has a great number of updated packages. It includes Linux kernel 6.8.0, systemd v255.4, LLVM 18, GCC 13.2.0 (with an experimental version of the unreleased GCC 14), GNU C Library (glibc) 2.39, and Binutils 2.42. Other changes include updates to Python 3.12 as the default Python, OpenJDK 21, Rust 1.75, Go 1.22, Ruby 3.2.3, and Perl 5.38.2.
The new Firmware Updater application is a nice addition, but it is something of a black box. It displays a list of system firmware along with upgrades (and downgrades) that can be applied, as well as options to update their checksums and to verify the firmware. Unfortunately, it doesn't provide links to the original download site for firmware or give the user any way to even see the checksums. Clicking "Verify Firmware" pops up a dialog that asks if the user wants to verify the firmware. Clicking "OK" just closes the dialog box without any indication whether the check was performed or if it passed.
![[Ubuntu Firmware Updater]](https://static.lwn.net/images/2024/System-Firmware-sm.png "Ubuntu Firmware Updater")
There are a few security enhancements worth noting. For example, unprivileged user namespaces are now restricted to prevent potential kernel exploits. Because many applications, like Buildah, Firefox, Podman, Thunderbird, and others, use user namespaces, there are nearly 100 AppArmor profiles allowing well-known applications to use user namespaces. If an application isn't in that list, such as Bubblewrap, it's reasonably easy to create an AppArmor profile that allows the application to create a user namespace. It's also possible to disable the restriction entirely, though that hasn't proven necessary so far in my day-to-day use.
APT now expects RSA signing keys of 2048 bits or more, and will warn when trying to install packages signed with 1024-bit keys. The release notes indicate that the warning will become an error when APT 2.8.0 is introduced at a later date. (The current version is 2.7.14.)
Not entirely baked
There is certainly no rush for Ubuntu users to upgrade right now with standard support for 22.04 LTS through 2027. Numbat will receive standard security maintenance (in other words, free updates without requiring an account) through 2029. Those who have an Ubuntu Pro account can receive updates for 24.04 LTS through 2034. See the release cycle page for full details.
Overall, Noble Numbat is a good release, but it feels much less finished than one might expect for an LTS release. This may, in part, be because the release cycle was interrupted by the XZ situation. Canonical opted to delay the beta by one week and do a full rebuild of all packages, but stuck to the April 25 release date. An extra week (or more) to address bugs might have been in order. Ubuntu users who prefer stability over novelty may wish to sit out the upgrade until 24.04.1 is available later this year.
A leadership crisis in the Nix community
On April 21, a group of anonymous authors and non-anonymous signatories published a lengthy open letter to the Nix community and Nix founder Eelco Dolstra calling for his resignation from the project. They claimed ongoing problems with the project's leadership, primarily focusing on the way his actions have allegedly undermined people nominally empowered to perform various moderation and governance tasks. Since its release, the letter has gained more than 100 signatures.
Decision-making authority
The Nix project is governed by the
NixOS Foundation, a non-profit organization
that handles the project's finances and legal responsibilities. The foundation
itself is headed by a board with five voting members, chaired by Dolstra.
There are no term limits, and the board selects its own membership and chair.
According to
the board's team page, its responsibilities include handling
"administrative, legal, and financial tasks
", sponsorships and donations,
funding for "community events and efforts
", and acting as an arbiter in
case of conflicts in the community. Notably, the board "is not responsible
for technical leadership, decisions, or direction
", nor is it expected to
handle all decision making. The board is responsible for
providing "a framework for teams
to self-organize
", including a duty to "[h]and out the credentials and
permissions required for the teams' work
".
The open letter has several related complaints, but the most central one is that they allege Dolstra has repeatedly strong-armed the board and members of other community teams to overrule their decisions:
For example, after months of discussion on sponsorship policy in the board, with consensus having been formed on a policy that allows community veto of NixCon sponsors, Eelco (and Graham [Christensen], at the same time) appeared at the open board call over 45 minutes in, and began re-litigating the issue of whether we need to limit sponsorship to begin with, which had already been agreed upon by everyone but him.
Christensen is Dolstra's co-founder at
Determinate
Systems.
The letter lists other examples, such as Dolstra blocking longtime
contributors from becoming code reviewers or blocking a build-system change that
had made it through the RFC process.
The letter
concludes that Dolstra is essentially
leveraging social power from being the founder of the project to overrule
decisions that are nominally supposed to be made collaboratively.
In short, Dolstra is acting as "the effective Benevolent Dictator for Life
(BDFL)
" of the
project, even though the NixOS Foundation's charter doesn't grant anyone that
authority.
The letter
says this leads to "a culture of responsibility without authority
" that
erodes contributors' desire to continue working on the project. It specifically
mentions the moderation team as an example of this, saying that its members are
"in fear of
their authority being undermined directly by Eelco or indirectly through the
Foundation
".
When asked to comment on the concerns raised in the letter, members of the NixOS moderation team responded:
Overall we think that the letter describes the situation of the moderation team fairly well. We have been operating in an emergency mode most of the time for over half a year now. Our team retention is at an all time low, and we are barely able to keep up with recruiting new members as old ones quit. Right now the moderation team is down to four people, including two who desire to leave as soon as a replacement is found, not counting another moderator who left last week.
To the extent that the moderation team feels disempowered, this is mostly because of heavy antagonism from some community members or risks of destabilizing the community, and not because of an actual lack of power. Most of that is a reflection of a deeper cultural conflict within the community and not directly related to the foundation board.
Despite slightly disagreeing with the source of the issue, they went on to acknowledge that Dolstra had impeded several attempts to improve the situation, and said that they understood many community members' complaints. The team also called the situation itself "a deep structural and cultural issue involving many people".
Pierre Bourdon, a long-time contributor to Nix, posted on Mastodon about his experience working on NixOS, stating that while he disagrees with the tone and approach of the open letter, the factual statements about Dolstra's leadership match his own experience.
Conflicts of interest
The letter also alleges several conflicts of interest, primarily concerning
Dolstra's employer, Determinate Systems.
Anduril, a military contractor that uses NixOS, has repeatedly
attempted to become a sponsor of NixCon, which did not go over well with the
community, as reflected in the minutes of
the board meeting on March 20. The letter says Dolstra pushed
strongly for the inclusion of Anduril as a sponsor even after it became clear
that many core contributors disagreed. Anduril was eventually dropped as a sponsor
for both NixCon 2023
and NixCon 2024 after community
pressure.
[Thanks to Martin Weinelt for pointing out that
Anduril did end up sponsoring NixCon
2024.]
On April 10, Théophane Hufschmitt, the secretary of the board, shared
an update on the board's
new sponsorship policy. Hufschmitt expressed the board's apologies for the
way the situation was handled, and promised that "we will prioritize
transparency, inclusivity, and responsiveness in our decision-making
processes
."
That same day, Samuel Dionne-Riel
stated that Dolstra had refused to clarify
whether he had a relationship with Anduril and
asked
Christensen, a co-founder of Determinate Systems: "Does DetSys have or had
relationships with Anduril?
" Christensen
replied:
"Did you know this
category of question is pretty much impossible to answer because NDAs are a
thing?
"
This isn't the only time Dolstra has appeared to avoid disclosing potential
conflicts of interest; the letter alleges that
he kept his status as a founder of Determinate Systems secret for
some months (a claim Dolstra later denied), and that
this is especially worrying in light of some of the technical
promises that Determinate Systems makes to customers. The company produces its
own installer for Nix that the company promises will provide stable support for some
Nix features. The letter states: "This is fine, however, it is questionably
acceptable to do that while employing the lead developer of CppNix
[the main Nix implementation] and saying
nothing about how this will interact with the team's [decision-making]
autonomy.
"
The concerns are not entirely theoretical, either;
the main Nix installer has been
broken in various ways since version 2.18 in September 2023.
Call to action
The final section of the letter calls for Dolstra's resignation from the board, suggesting that he should also completely disengage from the project for at least six months, to give the rest of the board time to reform the project's governance.
This document should be seen as the canary in the coal mine for what many people have been feeling for years and does not exhaustively cover absolutely all problems in the community, but we hope it is enough to justify action.
The letter ends by suggesting that if Dolstra doesn't resign, the signatories would switch to and support a fork of the project. I contacted several of the signatories to ask whether they'd be willing to provide additional commentary on why they believed a letter like this to be a necessary step. Haydon Welsh responded:
I signed the letter because it was clear that every other team member was sick and tired of Eelco, and so I saw it only right if that's their only hope to regain enthusiasm for the project. No open-source project should die or be hard-forked because of one person, that destroys a lot of the purpose for being open-source.
Kiara Grouwstra had stronger feelings on the matter:
While I want a full rotation of members on the NixOS board, as well as changes to its goal and structure so as to better incorporate the community including marginalized perspectives, my friend convinced me the polemic response would not sit well with the moderators, and shared with me the draft open letter about Eelco's role, which I opted to settle for as the lower-hanging fruit right now.
On April 27, Xe Iaso wrote a blog post about xer perspective on the matter, stating that at this point a fork is both inevitable and doomed. Even if the actions called for in the letter do come about, the difficult situation is already having an impact on the Nix community. On April 21, Nixpkgs contributor Kamila Borowska resigned from the project. On April 25, Mario Rodas, who had contributed more than 250 packages, followed suit. In total, 24 maintainers have left.
Dolstra's response
On April 26, Dolstra posted
a response to the letter.
He states that the role of the board is to handle the
financial and legal work, not to run the Nix community.
He also claims that he has had "very little involvement in Nixpkgs and NixOS
in recent years
".
Dolstra goes on to state: "I am just one member of the five-member Nix team
and hold no more formal authority than the others in determining the direction
of the team.
"
While this is true, it does not directly refute the
letter's claims that Dolstra exceeds the formal authority granted to him.
Dolstra also reiterated his position that NixCon should not refuse Anduril's
sponsorship, stating: "It is my opinion that it is not for us, as open source
software developers, to decide whose views are valid and whose are not, and to
allow or disallow project or conference participation as a result.
"
Dolstra does, however, explicitly refute the claim that his involvement in
Determinate Systems was at all secret: "My role,
participation, and focus on the good work being done at Determinate Systems have
been public knowledge since the company's inception
". He goes on to say that
the claim that Determinate Systems seeks to have an outsized influence on the
community is "patently false
".
He ends his response by inviting community members who feel unwelcome in the Nix community to work for Determinate Systems instead:
I remain committed to creating a community where everyone feels seen, heard, and valued, and I will not let unfounded accusations detract from this important work. I encourage everyone reading this who feels that they have not been heard or feels displaced to join the Determinate Systems community as we continue working to make Nix as easy to use and as impactful as possible.
It is difficult to predict where the Nix community will go from here, and what the eventual fate of any forks will be. For now, Dolstra remains the chair of the board — a position he seems unlikely to give up under pressure from the letter's signatories.
Security patterns and anti-patterns in embedded development
When it comes to security, telling developers to do (or not do) something can be ineffective. Helping them understand the why behind instructions, by illustrating good and bad practices using stories, can be much more effective. With several such stories Marta Rybczyńska fashioned an interesting talk about patterns and anti-patterns in embedded Linux security at the Embedded Open Source Summit (EOSS), co-located with Open Source Summit North America (OSSNA), on April 16 in Seattle, Washington.
![[Marta Rybczyńska]](https://static.lwn.net/images/conf/2024/ossna/Marta-Rybczyńska-ossna-sm.png "Marta Rybczyńska")
Rybczyńska started the talk by discussing her relevant experience as a security consultant as well as being a developer by training. (Though not mentioned, she is a frequent guest author for LWN as well.) She then moved on to her picks for recent, high-profile examples, including bricked trains, HTTP/2 protocol implementation issues, leaked signing keys, and the XZ backdoor.
The little engines that couldn't
The first story touched on embedded security practices for devices where security and safety are of the utmost priority: trains. A Polish railway operator, the Lower Silesian Railway (LSR), encountered problems with trains purchased from Newag. LSR sent the trains out to be serviced by Serwis Pojazdów Szynowych (SPS), a competing train maintenance provider, rather than Newag. SPS found that the trains would no longer start, and brought in a third party to investigate the software used in the trains. (A presentation on the investigation was given at the 37th Chaos Communication Congress in 2023.)
What they found, Rybczyńska said, was that the trains were intentionally bricked under certain conditions. For example, trains that had been stopped for a long period of time or trains that were at certain GPS coordinates that matched SPS repair facilities. The trains were also found to lock up on specific dates (possibly meant to force maintenance), and the researchers discovered "cheat codes" that could unlock the trains.
Rybczyńska identified several anti-patterns in this story. In addition to the apparent ransomware built into the firmware for the trains, they also suffered more general flaws. She mentioned that nearly every train had a different firmware version, and no indication of version control. "So we can have some doubts about the quality of the development process, right?" One might, she said, have doubts about the certification process that didn't detect any of these problems before certifying the trains for use in public transit. "I don't have access to the certification documents, so I'm not able to say what they're checking, but that's an interesting part."
Finally, Rybczyńska questioned the ethics of the developers for including functionality that would prevent third-party repairs and parts, or allow disabling a train according to its location. "Especially for the GPS conditions, because that is pretty obvious what it is going to do."
HTTP/2 implementations
Having ridden the train story to its conclusion, she then switched tracks to HTTP/2 implementations in embedded systems. She looked at CVE-2023-44487, a HTTP/2 rapid reset flaw that impacted NGINX, nghttp2, Apache Tomcat, Apache Traffic Server, and others. In this attack, a client sends multiple requests and then cancels them in rapid succession, causing the server to do extra work processing the requests. This can lead to a denial-of-service as the server is unable to process new incoming requests.
Part of the problem, said Rybczyńska, was a weakness in the HTTP/2 protocol itself. That does not excuse the vulnerabilities, however. She said developers were responsible for not just implementing standards, but anticipating what might happen. "The protocol is not protecting you from everything." (LWN has recently covered continuation-flood attacks on HTTP/2 that might have been prevented with better implementations of the protocol.)
She also asserted that web servers written for embedded systems were "way less affected than the other ones" because they are subject to more stringent resource allocations. Her thesis was that software written for resource-constrained systems, such as embedded systems, would be less likely to be vulnerable to some attacks. As an example of this, she cited lighttpd, a web server designed for low-resource usage compared to other popular web servers. Lighttpd is not considered vulnerable to CVE-2023-44487 in its default configuration. What it did differently, she said, was to process HTTP/2 frames in batches and set a limit of eight streams per client, rather than 100 or greater as recommended by the RFC. This meant that an attack that debilitated other web servers merely caused lighttpd to increase its resource usage.
Watch your keys
Next, she turned to an embarrassing incident for hardware vendor MSI from early 2023. The company was subject to a ransomware attack and data breach to the tune of 1.5TB of data. The stolen data included source code, firmware, and perhaps worst of all, image signing keys for UEFI firmware. Used correctly by a hardware vendor, the signing keys would allow the Intel Boot Guard system to verify firmware before loading it at boot time. In the hands of attackers it would allow distribution of UEFI bootkits that can bypass secure boot features on MSI devices using 11th through 13th generation Intel CPUs.
Rybczyńska identified several anti-patterns in this story that embedded developers should take pains to avoid. Firstly, she noted that the keys could not have been well-secured if they were caught up in a general data breach. Signing keys, she pointed out, should not be on a machine connected to a company's general network. Ideally, they would be stored on hardware tokens or systems that are air-gapped from the main network to reduce the chance they could be exfiltrated.
Better protection of signing keys could have prevented their exposure, but it's not a guarantee. MSI's other sin, in this case, was that the keys had no revocation mechanism. This means attackers can attempt to exploit any of the affected hardware through the entire life of the systems, with no way for MSI or Intel to revoke the vulnerable keys. The one positive in this story, she said, was that MSI had used a separate key for each product rather than a single signing key for all of its products.
XZ, of course
The XZ backdoor episode was a dominant topic at EOSS and OSSNA. If things had gone a bit differently, Rybczyńska said, the backdoor might have been caught by the Yocto project because XZ versions 5.6.0 and 5.6.1 broke the build. The failure to notice the backdoor was because Yocto's build-system maintainer didn't have time to investigate why the builds weren't working before the backdoor was discovered elsewhere.
The reason, or one reason, that compromised versions of XZ wouldn't build is that Yocto does not use the build scripts provided with the source tarball. This is in part because Yocto targets a broader set of compilers and architectures than mainstream Linux distributions. She surveyed the room and asked how many people really understood Autoconf's m4 scripts. In a room with about 100 attendees, few hands went up. "That's the issue," she said, "hide your backdoor in M4 scripts." Developers, she said, should be using languages for build systems that aren't obscure and therefore difficult to read.
She also called out, like many others, that developers need to consider their dependencies. She suggested that having a dependency on a project with a sole maintainer who is underfunded and overworked is something to be wary of. "It is important to consider your dependencies. Those projects maintained by the person in Nebraska, are you really sure you want to use them?"
Rybczyńska wrapped up by summing up some of the lessons learned from the stories in her talk, and reminded the audience that security practices evolve from real-world situations. "Security practices are there for a reason [...] if there's a security practice that is making your life harder, ask the security person why" it exists and see if there's another way to mitigate risk. Odds are, there's a story behind the practice.
[Thanks to the Linux Foundation, LWN's travel sponsor, for supporting our travel to this event.]
The state of realtime and embedded Linux
Linux, famously, appears in a wide range of systems. While servers and large data centers get a lot of the attention, and this year will always be the year of the Linux desktop, there is also a great deal of Linux to be found in realtime and embedded applications. Two talks held in the realtime and embedded tracks of the 2024 Open Source Summit North America provided listeners with an update on how Linux is doing in those areas. Work on realtime Linux appears to be nearing completion, while the embedded community is still pushing forward at full speed.
Finishing realtime
The realtime session was run as a panel discussion featuring Kate Stewart, Daniel Bristot de Oliveira, Sebastian Siewior, and an empty chair representing Thomas Gleixner who, with help from the airlines, missed his deadline for arrival to the conference. Bristot started by asking what has motivated the realtime community to do all of the work it has done. Stewart answered that there was a problem (the need for a version of Linux that could meet realtime response requirements), and a number of companies got together to fund it. The latest stage alone was an eight-year journey, but this project is getting close to completion.
Siewior added that there is not much core code left in the realtime repository; most of it is related to the ongoing printk() work. The rest is changes to drivers and such. Stewart said that the funding needed to finish this work properly is now available. Siewior noted that effort is going into backporting realtime-related fixes to older kernels as well.
Bristot said that work on scheduling and tooling is ongoing. People have been working on problems with realtime throttling for years. In an attempt to keep a runaway realtime process from killing the system, the kernel will only let realtime tasks use 95% of the available CPU time, even if nothing else is contending for the CPU. Realtime developers would like to get that 5% back, but without compromising the ability to recover a runaway system. Many of the proposed solutions, Bristot said, would have constrained the development community in the future as people came to depend on them. His conclusion from that experience is that "cutting corners is bad" and doesn't help in the long run.![[The realtime panel]](https://static.lwn.net/images/conf/2024/ossna/rt-panel-sm.png "The realtime panel")
The solution to the throttling problem that has emerged is deadline servers. The kernel's deadline scheduler runs tasks at an even higher priority than realtime tasks, meaning that it cannot be locked out by an out-of-control realtime task. A deadline server is a task, running under the deadline scheduler with a 5% CPU share, that runs normal (non-realtime) processes, if any need the CPU. Some work has had to be done to run the deadline server at the right time to minimize the impact on realtime tasks.
Stewart asked whether the upstreaming of the realtime code has had an effect on the rest of the kernel; Bristot answered that realtime discussions are now just a normal part of the kernel's development process rather than being a separate thing. Siewior observed that having the realtime code upstream has reduced interest in finishing the job. Bristot pointed out that there is a lot of useful code in the kernel that started in the realtime tree; now it is upstream and everybody benefits from it, but they forget where it came from.
An audience member asked what projects the realtime community was working on next. Bristot said that, so far, the focus has been almost exclusively on latency, but it is time to start thinking more about related problems. The scheduling of multiple tasks and optimizing response time for all of them is high on the list. Sharing a CPU with more than one realtime task can bring out more locking problems; that increases the pressure to, among other things, get the proxy execution work into the mainline.
Bristot raised a longstanding problem with the deadline scheduler: its admission-control algorithm (which decides whether a new deadline task can be accepted while still ensuring that all tasks will meet their deadlines) works globally across the entire system. A side effect of this design is that it is not possible to set CPU affinity for deadline tasks, but that is something that users want to be able to do. Disabling admission control allows users to place their tasks, but that takes away an important guarantee, and the global policy is inefficient anyway. So there is interest in finding ways to partition a system.
Stewart turned the discussion to how people can get involved with realtime Linux; Siewior was quick to point out that there is a need for better documentation. An audience member echoed that sentiment, saying that users are having to rediscover how to set up a realtime system; they would benefit from some better guides. He also noted that the real-time Linux analysis tool (RTLA) has proved to be helpful with this task, but it is just a beginning. Bristot answered that some things just take time; RTLA was born in 2010, but only really became useful years later.
Another audience member pressed this point; the need is urgent for guides to help users with setup, benchmarking, and so on. Bristot answered that "getting things right in the kernel creates momentum" that can solve this kind of problem — over time. A solution that is good for all use cases encourages further development. Now that it is easy to add new tools to RTLA, for example, others are contributing them.
Tim Bird said that he has been trying to convince people in the space sector that Linux is a realtime system, but "they aren't buying it". Realtime Linux still has a messaging problem, he said. RTLA doesn't help in this regard, it is a tool that "shows you all the ways Linux fails at realtime"; it gives the wrong kind of message. Bristot answered that realtime is not just about latency; solving a problem requires understanding the workload in question, adapting it to the Linux execution model, and using tools (like RTLA) to find misbehavior. Linux is like other operating systems in that regard. Siewior added that, if one buys a 100GB/sec network card, that kind of bandwidth will not just materialize right away. The system has to be tuned to get the expected level of performance; realtime is the same story.
Bristot insisted that Linux is a valid realtime option; with proper tuning and use of CPU isolation, he said, a RHEL system can achieve latency of less than 10µs. Bird said such results just lead to the impression that an expert user can get the needed response, but only after tweaking 100 tuning knobs. Bristot allowed that a certain amount of expertise is required, but said that the situation is getting better.
When an audience member asked whether the time has come for a detailed book about realtime on Linux, Siewior pointed to the realtime wiki as a starting point. He has been asking developers and users to provide updates, but complained that it never happens. Bristot suggested adding information to the kernel's documentation tree as a way to add momentum and encourage contributions; Stewart said that tends to raise the quality of the documentation as well. Alison Chaiken suggested splitting the kernel's lengthy command-line parameter documentation to provide a realtime-specific document; Siewior worried that splitting the documentation that way could create consistency problems over time.
Another audience member suggested eliminating all of those kernel parameters, making the realtime-specific tuning knobs modifiable at run time instead. Bristot said that would be a long and difficult task; Siewior added that there are quite a few parameters that can only be set at boot time.
As the session ran out of time, it wandered into some rather less-serious suggestions, including removing all of the code (that solves the problem of too many tuning knobs) or just asking some large-language model to spew out a bunch of useful realtime documentation. Bristot answered that ChatGPT "doesn't know a thing" about realtime Linux, so that otherwise entirely viable option was discarded, and the session came to a close.
Catching up with embedded Linux
The "state of embedded Linux" session was held the next day; it was run by Bird and Marta Rybczyńska. The overall impression was one of a great deal of ongoing activity, and a number of problems yet to be solved.
Rybczyńska began with an overview of recent kernel releases, pointing out the changes that are of specific interest to embedded-system developers:
- 6.4: the removal of the SLOB memory allocator, a document on building a trimmed kernel, the removal of MODULE_LICENSE() declarations from non-modular code, and user trace events.
- 6.5: better parallelization on the bring-up of x86 CPUs, a reorganization of 32-bit devicetree files, and a lot of ftrace and perf updates.
- 6.6: the ability to build a kernel without buffer heads, the eventfs filesystem, and x86 shadow stacks.
- 6.7: a parameter to disable 32-bit emulation on 64-bit x86 systems, the removal of Itanium architecture support, improvements to kernel samepage merging, and a number of printk() improvements.
- 6.8: initial deadline server support, the first driver written in Rust, a reorganization of some core networking data structures, the removal of the SLAB memory allocator, and data-type profiling for perf.
- 6.9 (upcoming): the ext2 filesystem has been deprecated, some significant kernel timer changes, work to reduce locking contention in the network stack, and the run-time modifiable energy model.
![[Marta
Rybczyńska]](https://static.lwn.net/images/conf/2024/ossna/MartaRybczynska-sm.png "Marta Rybczyńska") Also covered was the end of six-year support for the long-term stable
kernel releases. Users looking for longer support, Bird said, can look to
the Civil Infrastructure
Platform or the Ubuntu long-term releases — or they can follow the
stable updates and change kernel versions during a device's lifetime. "But
we never do that".
Also covered was the end of six-year support for the long-term stable
kernel releases. Users looking for longer support, Bird said, can look to
the Civil Infrastructure
Platform or the Ubuntu long-term releases — or they can follow the
stable updates and change kernel versions during a device's lifetime. "But
we never do that".
Rybczyńska mentioned a number of ongoing efforts, starting with work being done at TI to reduce boot times. This is especially of interest in the automotive world. This work seems to be focused on initializing devices in the boot loader, then passing them to the kernel in a fully ready state.
On the graphics front, she cited the NVK Vulkan driver for NVIDIA GPUs. Work is ongoing to improve the MTD-SPI-NOR subsystem for faster filesystem access, and the EROFS filesystem is getting caching and speed enhancements as well. The realtime work was mentioned as well. This portion of the talk concluded with a discussion of the kernel project starting to assign its own CVE numbers for vulnerabilities.
Bird took over to present a "rant" about system size — always a concern for embedded deployments. The removal of the SLOB allocator, which was intended for use on small systems, is something that can be accepted, he said; it was not really being used anymore. But, he complained, there were only two kernel releases between the time that SLOB was deprecated and when it was actually removed; embedded developers were unlikely to notice the deprecation in that time period, which should have been longer. The removal of SLAB in the same year didn't help either. He acknowledged the addition of the CONFIG_SLUB_TINY configuration option, which helps, but he said that SLUB will never be as small as SLOB was. Some users, he worried, have lost a useful kernel feature.
![[Tim
Bird]](https://static.lwn.net/images/conf/2024/ossna/TimBird-sm.png "Tim Bird") On the testing front, there was a
proposal to provide integration with GitLab's continuous-integration
(CI) system, but Linus Torvalds did
not like it. That proposal is thus dead, but there is still the
possibility that this kind of support could be added at lower levels of the
kernel "where Linus doesn't have to worry about it". The ability to run CI
testing right out of the box would make testing much easier, Bird said.
On the testing front, there was a
proposal to provide integration with GitLab's continuous-integration
(CI) system, but Linus Torvalds did
not like it. That proposal is thus dead, but there is still the
possibility that this kind of support could be added at lower levels of the
kernel "where Linus doesn't have to worry about it". The ability to run CI
testing right out of the box would make testing much easier, Bird said.
With regard to toolchains, GCC 13.2 was released in July 2023; the GCC 14 release is due at about any time and brings some interesting static-analyzer improvements. GCC, he said, is a useful testing program; it finds more bugs than any others. He mentioned that Bootlin makes available a set of prebuilt cross-toolchains for those who don't want to build their own.
Rybczyńska mentioned that the Yocto Project 5.0 release is coming "at any hour". This will be a new long-term-support release, and the first with generic Arm 64-bit support. This release is based on the 6.6 kernel.
In industry news, the Cyber Resilience Act (CRA) is progressing in Europe; it will require vendors to provide security updates for their products and perform due diligence on the components they incorporate. The final publication of the CRA is expected in October, and it will come into full force in 2027. Three years to prepare is not a long time, she said, given that there are a lot of associated standards that still need to be written.
The HDMI 2.1 specification is out. AMD wanted to write an open-source driver for HDMI 2.1, but the HDMI Forum blocked it, so there will be no free driver.
She concluded by mentioning that the Mars helicopter, after 72 flights, is grounded with damaged blades, and that mission has come to an end. We will surely see other missions taking Linux into space, though, she said.
Bird gave an overview of the conference situation; the Embedded Linux Conference is back to a twice-per-year schedule. The (northern-hemisphere) spring event will be held in North America, while the fall event will be in Europe. The next will be in Vienna in September. Some attendees dislike the move away from a standalone event in favor of colocation with large events like the Open Source Summit; Bird said that the move was driven by sponsorship (or the lack thereof).
The Embedded Linux Wiki, which is a longstanding resource for this community, recently lost funding for its system administrator. The good news is that the person involved has taken a job at the Linux Foundation and will continue to work on the wiki. The site is out of date in places and underutilized, he said, but it also contains a lot of useful material; volunteers to help are welcome.
Rybczyńska concluded by saying that the embedded community is doing well; it will be the year of embedded Linux yet again. Much of the needed kernel infrastructure for embedded Linux is in place now, she said, and there are still new developers showing up to help. The community's infrastructure needs some investment, but the community as a whole is in a good place.
[Thanks to the Linux Foundation, LWN's travel sponsor, for supporting our travel to this event.]
Support for the TSO memory model on Arm CPUs
At the CPU level, a memory model describes, among other things, the amount of freedom the processor has to reorder memory operations. If low-level code does not take the memory model into account, unpleasant surprises are likely to follow. Naturally, different CPUs offer different memory models, complicating the portability of certain types of concurrent software. To make life easier, some Arm CPUs offer the ability to emulate the x86 memory model, but efforts to make that feature available in the kernel are running into opposition.CPU designers will do everything they can to improve performance. With regard to memory accesses, "everything" can include caching operations, executing them out of order, combining multiple operations into one, and more. These optimizations do not affect a single CPU running in isolation, but they can cause memory operations to be visible to other CPUs in a surprising order. Unwary software running elsewhere in the system may see memory operations in an order different from what might be expected from reading the code; this article describes one simple scenario for how things can go wrong, and this series on lockless algorithms shows in detail some of the techniques that can be used to avoid problems related to memory ordering.
The x86 architecture implements a model that is known as "total store ordering" (TSO), which guarantees that writes (stores) will be seen by all CPUs in the order they were executed. Reads, too, will not be reordered, but the ordering of reads and writes relative to each other is not guaranteed. Code written for a TSO architecture can, in many cases, omit the use of expensive barrier instructions that would otherwise be needed to force a specific ordering of operations.
The Arm memory model, instead, is weaker, giving the CPU more freedom to move operations around. The benefits from this design are a simpler implementation and the possibility for better performance in situations where ordering guarantees are not needed (which is most of the time). The downsides are that concurrent code can require a bit more care to write correctly, and code written for a stricter memory model (such as TSO) will have (possibly subtle) bugs when run on an Arm CPU.
The weaker Arm model is rarely a problem, but it seems there is one situation where problems arise: emulating an x86 processor. If an x86 emulator does not also emulate the TSO memory model, then concurrent code will likely fail, but emulating TSO, which requires inserting memory barriers, creates a significant performance penalty. It seems that there is one type of concurrent x86 code — games — that some users of Arm CPUs would like to be able to run; those users, strangely, dislike the prospect of facing the orc hordes in the absence of either performance or correctness.
TSO on Arm
As it happens, some Arm CPU vendors understand this problem and have, as Hector Martin described in this patch series, implemented TSO memory models in their processors. Some NVIDIA and Fujitsu CPUs run with TSO at all times; Apple's CPUs provide it as an optional feature that can be enabled at run time. Martin's purpose is to make this capability visible to, and controllable by, user space.
The series starts by adding a couple of new prctl() operations. PR_GET_MEM_MODEL will return the current memory model implemented by the CPU; that value can be either PR_SET_MEM_MODEL_DEFAULT or PR_SET_MEM_MODEL_TSO. The PR_SET_MEM_MODEL operation will attempt to enable the requested memory model, with the return code indicating whether it was successful; it is allowed to select a stricter memory model than requested. For the always-TSO CPUs, requesting TSO will obviously succeed. For Apple CPUs, requesting TSO will result in the proper CPU bits being set. Asking for TSO on a CPU that does not support it will, as expected, fail.
Martin notes that the code is not new: "This series has been brewing in
the downstream Asahi Linux tree for a while now, and ships to thousands of
users
". Interestingly, Zayd Qumsieh had posted a
similar patch set one day earlier, but that version only implemented
the feature for Linux running in virtual machines on Apple CPUs.
Unfortunately for people looking forward to faster games on Apple CPUs,
neither patch set is popular with the maintainers of the Arm architecture
code in the kernel. Will Deacon expressed
his "strong objection
", saying that this feature would result in a
fragmentation of user-space code. Developers, he said, would just enable
the TSO bit if it appears to make problems go away, resulting in code that
will fail, possibly in subtle ways, on other Arm CPUs. Catalin Marinas,
too, indicated
that he would block patches making this sort of implementation-defined
feature available.
Martin responded that fragmentation is unlikely to be a problem, and pointed to the different page sizes supported by some processors (including Apple's) as an example of how these incompatibilities can be dealt with. He said that, so far, nobody has tried to use the TSO feature for anything that is not an emulator, so abuse in other software seems unlikely. Keeping it out, he said, will not improve the situation:
There's a pragmatic argument here: since we need this, and it absolutely will continue to ship downstream if rejected, it doesn't make much difference for fragmentation risk does it? The vast majority of Linux-on-Mac users are likely to continue running downstream kernels for the foreseeable future anyway to get newer features and hardware support faster than they can be upstreamed. So not allowing this upstream doesn't really change the landscape vis-a-vis being able to abuse this or not, it just makes our life harder by forcing us to carry more patches forever.
Deacon, though, insisted
that, once a feature like this is merged, it will find uses in other
software "and we'll be stuck supporting it
".
If this patch is not acceptable, it is time to think about alternatives. One is to, as Martin described, just keep it out-of-tree and ship it on the distributions that actually run on that hardware. A long history of addition by distributions can, at times, eventually ease a patch's way past reluctant maintainers. Another might be to just enable TSO unconditionally on Apple CPUs, but that comes with an overall performance penalty — about 9%, according to Martin. Another possibility was mentioned by Marc Zyngier, who suggested that virtual machines could be started with TSO enabled, making it available to applications running within while keeping the kernel out of the picture entirely.
This seems like the kind of discussion that does not go away quickly. One of the many ways in which Linux has stood out over the years is in its ability to allow users to make full use of their hardware; refusing to support a useful hardware feature runs counter to that history. The concerns about potential abuse of this feature are also based in long experience, though. This is a case where the development community needs to repeat another part of its long history by finding a solution that makes the needed functionality available in a supportable way.
Giving Rust a chance for in-kernel codecs
Video playback is undeniably one of the most important features in modern consumer devices. Yet, surprisingly, users are by and large unaware of the intricate engineering involved in the compression and decompression of video data, with codecs being left to find a delicate balance between image quality, bandwidth, and power consumption. In response to constant performance pressure, video codecs have become complex and hardware implementations are now common, but programming these devices is becoming increasingly difficult and fraught with opportunities for exploitation. I hope to convey how Rust can help fix this problem.
Some time ago, I proposed to the Linux media community that, since codec data is particularly sensitive, complex, and hard to parse, we could write some of the codec drivers in Rust to benefit from its safety guarantees. Some important concerns were raised back then, in particular that having to maintain a Rust abstraction layer would impose a high cost on the already overstretched maintainers. So I went back to the drawing board and came up with a new, simpler proposal; it differs a bit from the general flow of the Rust-for-Linux community so far by realizing that we can convert error-prone driver sections without writing a whole layer of Rust bindings.
The dangers of stateless decoders
Most of my blog posts at Collabora have focused on the difference between stateful and stateless codec APIs. I recommend a quick reading of this one for an introduction to the domain before following through with this text. This talk by my colleague Nicolas Dufresne is also a good resource. Stateless decoders operate as a clean slate and, in doing so, they require a lot of metadata that is read directly from the bit stream before decoding each and every frame. Note that this metadata directs the decoding, and is used to make control-flow decisions within the codec; erroneous or incorrect metadata can easily send a codec astray.
User space is responsible for parsing this metadata and feeding it to the drivers, which perform a best-effort validation routine before consuming it to get instructions on how to proceed with the decoding process. It is the kernel's responsibility to comb through and transfer this data to the hardware. The parsing algorithms are laid out by the codec specification, which are usually hundreds of pages long and subject to errata like any other technical document.
Given the above, it is easy to see the finicky nature of stateless decoder drivers. Not long ago, some researchers crafted a program capable of emitting a syntactically correct but semantically non-compliant H.264 stream exploiting the weaknesses that are inherent to the decoding process. Interested readers can refer themselves to the actual paper.
The role of Video4Linux2 codec libraries
A key aspect of hardware accelerators is that they implement significant parts of a workload in hardware, but often not all of it. For codec drivers in particular, this means that the metadata is not only used to control the decoding process in the device, it is also fed to codec algorithms that run in the CPU.
These codec algorithms are laid out in the codec's specification, and it would not make sense for each driver to have a version of that in their source code, so that part gets abstracted away as kernel libraries. To see the code implementing these codecs, look at files like drivers/media/v4l2-core/v4l2-vp9.c, v4l2-h264.c, and v4l2-jpeg.c in the kernel sources.
What's more, with the introduction of more AV1 drivers and the proposed V4L2 Stateless Encoding API, the number of codec libraries will probably increase. With the stateless encoding API, a new challenge will be to capture parts of the metadata in the kernel successfully, bit by bit, while parsing data returned from the device. For more information on the stateless encoding initiative, see this talk, by my colleague Andrzej Pietrasiewicz or the mailing-list discussion. A tentative user-space API for H.264 alongside a driver for Hantro devices was also submitted last year, although the discussion is still on a RFC level.
Why Rust?
Security and reliability are paramount in software development; in the kernel, initiatives aimed at improving automated testing and continuous integration are gaining ground. As much as this is excellent news, it does not fix many of the hardships that stem from the use of C as the chosen programming language. The work being done by Miguel Ojeda and others in the Rust-for-Linux project has the potential to finally bring relief to problems such as complex locking, error handling, bounds checking, and hard-to-track ownership that span a large number of domains and subsystems.
Codec code is also plagued by many of the pitfalls listed above and we have discussed at length about the finicky and error-prone nature of codec algorithms and metadata. Said algorithms, as we've seen, will use the metadata to guide the control flow on the fly and also to index into various memory locations. That has been shown to be a major problem in the user-space stack, and the problem is even more critical at the kernel level.
Rust can help by making a whole class of errors impossible, thus significantly reducing the attack surface. In particular, raw pointer arithmetic and problematic memcpy() calls can be eliminated, array accesses can be checked at run time, and error paths can be greatly simplified. Complicated algorithms can be expressed more succinctly through the use of more modern abstractions such as iterators, ranges, generics, and the like. These add up to a more secure driver and, thus, a more secure system.
Porting codec code to Rust, piece by piece
If adding a layer of Rust abstractions is deemed problematic for some, a cleaner approach can focus on using Rust only where it matters by converting a few functions at a time. This technique composes well, and works by instructing the Rust compiler to generate code that obeys the C calling convention by using the extern "C" construct, so that existing C code in the kernel can call into Rust seamlessly. Name-mangling also has to be turned off for whatever symbols the programmer plans to expose, while a [repr(C)] annotation ensures that the Rust compiler will lay out structs, unions, and arrays as C would for interoperability.
Once the symbol and machine code are in the object file, calling these functions now becomes a matter of matching signatures and declarations between C and Rust. Maintaining the ABI between both layers can be challenging but, fortunately, this is a problem that is solved by employing cbindgen, a standalone tool from Mozilla that is capable of generating an equivalent C header from a Rust file.
With that header in place, the linker will do the rest, and a seamless transition into Rust will take place at run time. Once in Rust land, one can freely call other Rust functions that do not have to be annotated with #[no_mangle] or extern "C", which is why it's advisable to use the C entry point only as a facade for the native Rust code:
// The C API for C drivers.
pub mod c {
use super::*;
#[no_mangle]
pub extern "C" fn v4l2_vp9_fw_update_probs_rs(
probs: &mut FrameContext,
deltas: &bindings::v4l2_ctrl_vp9_compressed_hdr,
dec_params: &bindings::v4l2_ctrl_vp9_frame,
) {
super::fw_update_probs(probs, deltas, dec_params);
}
In this example, v4l2_vp9_fw_update_probs_rs() is called from C, but immediately jumps to fw_update_probs(), a native Rust function where the actual implementation lives.
In a C driver, the switch is as simple as calling the _rs() version instead of the C version. The parameters needed by a Rust function can be neatly packed into a struct on the C side, freeing the programmer from writing abstractions for a lot of types.
Putting that to the test
Given the ability to rewrite error-prone C code into Rust one function at a time, I believe it is now time to rewrite our codec libraries, together with any driver code that directly accesses the bit stream parameters. Thankfully, it is easy to test codec drivers and their associated libraries, at least for decoders.
The Fluster tool by Fluendo can automate conformance testing by running a decoder and comparing its results against that of the canonical implementation. This gives us an objective metric for regressions and, in effect, tests the whole infrastructure: from drivers, to codec libraries and, even, the V4L2 framework. My plan is to see Rust code being tested on KernelCI in the near future so as to assess its stability and establish a case for its upstreaming.
By gating any new Rust code behind a KConfig option, users can keep running the C implementation while the continuous-integration system tests the Rust version. It is by establishing this level of trust that I hope to see Rust gain ground in the kernel.
Readers willing to judge this initiative may refer to the patch set I sent to the Linux media mailing list. It ports the VP9 library written by Pietrasiewicz into Rust as a proof of concept, converting both the hantro and rkvdec drivers to use the new version. It then converts error-prone parts of rkvdec itself into Rust, which encompasses all code touching the VP9 bit stream parameters directly, showing how Rust and C can both coexist within a driver.
So far, only one person has replied, noting that the patches did not introduce any regressions for them. I plan on discussing this idea further in the next Media Summit, the annual gathering of the kernel media developers that is yet to take place this year.
In my opinion, not only should we strive to convert the existing libraries to Rust, but we should also aim to write the new libraries that will invariably be needed directly in Rust. If this proves successful, I hope to show that there will be no more space for C codec libraries in the media tree. As for drivers, I hope to see Rust used where it matters: in places where its safety and improved ergonomics proves worth the hassle.
Getting involved
Those willing to contribute to this effort may start by introducing themselves to video codecs by reading the specification for their codec of choice. A good second step is to refer to GStreamer or FFmpeg to learn how stateless codec APIs can be used to drive a codec accelerator. For GStreamer, in particular, look for the v4l2codecs plugin. Learning cbindgen is better accomplished by referring to the cbindgen documentation provided by Mozilla. Lastly, reading through a codec driver like rkvdec and the V4L2 memory-to-memory stateless video decoder interface documentation can also be helpful.
Python JIT stabilization
On April 11, Brandt Bucher posted PEP 744 ("JIT Compilation"), which summarizes the current state of Python's new copy-and-patch just-in-time (JIT) compiler. The JIT is currently experimental, but the PEP proposes some criteria for the circumstances under which it should become a non-experimental part of Python. The discussion of the PEP hasn't reached a conclusion, but several members of the community have already raised questions about how the JIT would fit into future iterations of the Python language.
Bucher initially provided these criteria, but said that he expected the discussion to add more:
The JIT will become non-experimental once all of the following conditions are met:
- It provides a meaningful performance improvement for at least one popular platform (realistically, on the order of 5%).
- It can be built, distributed, and deployed with minimal disruption.
- The Steering Council, upon request, has determined that it would provide more value to the community if enabled than if disabled (considering tradeoffs such as maintenance burden, memory usage, or the feasibility of alternate designs).
LLVM
Marc-André Lemburg had several questions about Bucher's PEP. Lemburg pointed out that the "Rationale" section discusses LLVM as an alternative to the JIT, but the "Support" section implies it is a required dependency, and asked whether the JIT does use LLVM. Michael G Droettboom clarified that the new JIT uses LLVM as a build-time dependency, but not a run-time dependency. This is because the JIT uses a copy-and-patch architecture, instead of the more usual approach of using an existing code generator (like LLVM) at run time.
Bucher expanded on Droettboom's clarification, saying that LLVM is used to compile each "micro-op" instruction into a blob of machine code. The JIT stitches these blobs together together at runtime. LLVM is needed to compile the micro-ops, instead of whichever C compiler is used for the rest of the build, because it is the only C compiler that supports mandatory tail-call optimization — replacing a function call directly before a return with a jump to the called function. The Python interpreter uses a continuation-passing style that results in lots of tail calls that would, if they were not converted into jumps, result in a stack overflow. Bucher's response did clarify that building Python on platforms without LLVM remains possible if the JIT is disabled, which will always remain an option.
Patents
Lemburg also questioned whether any patents applied to the design of the JIT, to
which Droettboom and Bucher replied that they were not aware of any. Droettboom
wondered whether Python had a standard process for how to check in cases like
this. Ken Jin
chimed in to say: "IIRC, the trace trees technique or tracing JITs
in general (I forgot which one) are patented by UC Irvine/ Andreas Gal and
Michael Franz.
" He cited patent US8769511B2,
which was granted in 2014 and remains active until 2029.
He believes that the University of California has agreed to let open-source projects use the
technique without being sued.
There may be other relevant patents, however. Lemburg
pointed out that patent research is "hard and expensive
", and that the
paper describing the copy-and-patch JIT technique was written by employees of
Stanford, "so it wouldn't be surprising to find that a patent application is
underway.
" He was also unable to corroborate whether the University of
California has the stated policy, and suggested that perhaps the Python Software
Foundation (PSF) could look into setting up a patent license pool for PSF
sponsors to mitigate the risk of being sued for patent infringement. Python is
already part of the Open Invention
Network, a "patent non-aggression community" of companies that have pledged
not to assert patents over core open-source software projects.
Daniele Nicolodi
asked why the JIT was "any more of a concern patent wise than any other part
of CPython?
" Lemburg
clarified that is wasn't, but that the recent advancements in JIT technologies
combined with the clever new copy-and-patch technique were enough to prompt the
question.
Performance
Antoine Pitrou questioned whether the JIT's approach would be able to provide the desired level of performance. The PEP is clear that the JIT's current performance is only on-par with the interpreter, even though many of the planned improvements are already done.
It seems there is a general contradiction between working on tiny unit of works (micro-ops) and using a JIT compilation scheme that doesn't optimize across micro-ops. Is it possible to break out of this contradiction while still [benefiting] from the advantages of the copy-and-patch approach?
Jin
acknowledged that using micro-ops instead of normal bytecode instructions has an
inherent performance penalty — "between 1-4% performance loss on
pyperformance
" — but thought that improvements to
the trace optimizer could win some of that back.
Currently, it doesn't do much other than eliminate some type
checks and guards, but the CPython developers have laid the groundwork "for
significantly more optimizations in 3.14
", Jin said.
Bucher wrote at length about the future optimizations that could be applied to the JIT, including optimizations that work across micro-ops or that fuse them together into "super-instructions" that LLVM could optimize together. He emphasized that the list Pitrou cites are only the optimizations that were planned for version 3.13. That version of Python has a feature freeze for the first beta release in three weeks; Bucher didn't expect any of the planned improvements except top-of-stack caching to make it into the release:
This is one where we're not exactly sure how much it will win us, so we're just going to do it and measure. It's essentially cutting down tons of memory traffic and avoiding trips to and from the heap for things that could just be kept in machine registers, so I'm hopeful that the results will be significant… and there's a chance that it would pay off even more with Clang 19's new preserve_none calling convention, which it looks like we'll need to wait for.
The latest release of LLVM (and Clang) at the time of writing is version 18.1.4. If the project's release schedule continues as planned, version 19 is expected in September 2024.
What would be enabled
To help explain under what conditions the JIT would actually run, Diego Russo put together a diagram showing exactly that. If the JIT is disabled at compile time, it is never activated. If it is enabled at compile time, it will only run for functions that are hot enough. Those functions first run through the "tier-2" intermediate representation (IR) optimizer, and then are processed either by the JIT or by the tier-2 interpreter for debugging.
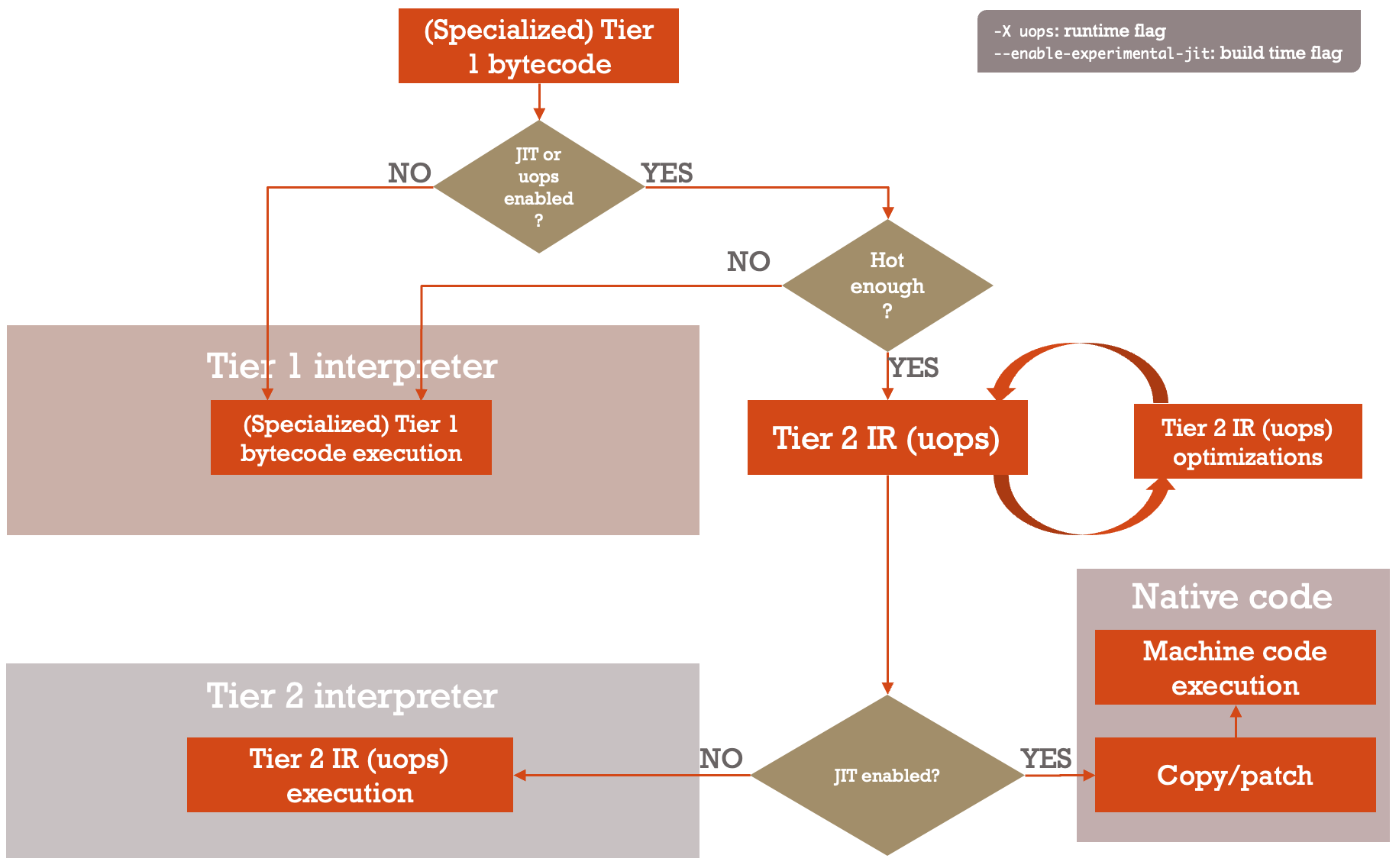
Russo also questioned whether it made sense to add a mechanism to enable or disable the JIT at run time, observing that the only configuration is at build time currently. Bucher agreed that would be desirable. Victor Stinner wondered about the feasibility of having a way to have Python compiled with JIT support, but have it disabled at run time by default — an option that might simplify packaging Python for distributions like Fedora that want Python to be stable, but also want to let users experiment with the JIT.
Near the end of the discussion, Guido van Rossum clarified what would definitely be in Python 3.13. The new tier-2 infrastructure would be part of the release, but there is no advantage to enabling it for end users, since the JIT is not yet more performant than the "tier 1" interpreter. The tier-2 interpreter is only used for debugging and ensuring the correctness of the tier-2 IR; it is the JIT that is expected to eventually provide better performance. The JIT will remain experimental, at least for 3.13, but Van Rossum expects the JIT (but not the tier-2 interpreter) to eventually be performant enough to be enabled by default:
I don't think we'll ever make the tier 2 interpreter the default, as according to our benchmarks it is not competitive with tier 1 – it's the JIT (which uses the same IR but instead of another interpreter translates it to machine code) that is the long-term focus of our efforts.
Despite the length of the discussion, the thread has not yet reached a consensus on whether there are any desirable conditions beyond the three Bucher originally proposed. If there are no unforeseen objections, and Bucher's planned performance improvements pan out, the JIT could be made non-experimental as soon as Python 3.14 in October 2025. On the other hand, the JIT has not yet actually demonstrated a performance win over the existing adaptive specializing interpreter, so it may still be some time before it is enabled for good.
Page editor: Jonathan Corbet
Inside this week's LWN.net Weekly Edition
- Briefs: run0; Dolstra steps down; Ubuntu 24.04 LTS; Amarok 3.0; Git 2.45.0; GNOME financials; GNU nano 8.0; Yocto 5.0; Quotes; ...
- Announcements: Newsletters, conferences, security updates, patches, and more.