Osobní poznámka
Když jsem před rokem a půl psal první článek první série, nazval jsem jej „Co to znamená „pořádně“ otestovat webovou aplikaci?“. Redakce mi tehdy doporučovala změnit tento název na „Jak pořádně otestovat webovou aplikaci“. Na návrh jsem nepřistoupil s odůvodněním, že jsem tehdy neměl dostatek zkušeností na to, abych mohl takový titulek s čistým svědomím použít. Článek tedy vyšel pod původním názvem.
Ani dnes, kdy už jsem zmíněnou webovou aplikaci otestoval již třetí sadou testů, si stále tak úplně nedovolím použít navrhovaný název „Jak pořádně otestovat webovou aplikaci“. I když jsem se totiž dostal do stavu poznání, kdy mohu říci, že testování zvládáme od začátku do konce, je toto testování zaměřeno stále jen na oblast funkcionálních testů a jejich podmnožiny – testů akceptačních. K úplnému otestování tedy stále chybějí provést další typy testů z dimenze kvality FURPS+ (Functionality, Usability, Reliability, Performance, Supportability). Ty ale pro tento zcela specifický typ a zamýšlený účel testované aplikace nepovažuji v tuto chvíli za potřebné. Což ale samozřejmě neznamená, že bych tyto testy obecně považoval za zbytečné.
Tato minisérie bude mít dvě části – v první budou popsány mé zkušenosti ze třetí fáze projektu. Cílem je opravdu jen předání zkušeností a to jak negativních, tak i pozitivních, což si jako pracovník z akademické sféry mohu dovolit. Pokud bych pracoval ve firemní sféře, samozřejmě bych se těmi negativními veřejně nechlubil. Věřím, že tyto (negativní) zkušenosti mohou většinu odborníků pobavit a nějakou množinu začátečníků uchránit od stejných chyb.
Ve druhé části budou popsány postupy akceptačního testování pomocí Robot Frameworku.
Testovaná aplikace
Aplikace je poměrně podrobně popsána v článku Automatické testování webových aplikací: souhrnný přehled výsledků případně ještě podrobněji na stránkách projektu TbUIS (https://projects.kiv.zcu.cz/tbuis/web/). Pokud byste si chtěli aplikaci vyzkoušet, pak v menu Home je vlevo dole odkaz Database content, ve kterém jsou uvedeny všechny potřebné údaje pro přihlášení.
Pro stručné uvedení do problematiky celého projektu zde jen shrnu, že se jedná o pseudorealistickou netriviální aplikaci, která má sloužit pro výzkum nových testovacích metod. Do „bezchybné“ (tím je míněno „důkladně otestované“, tj. „s velkou mírou pravděpodobnosti bezchybné“) aplikace lze uměle injektovat defekty. Injekce defektů již byla provedena a v současné době tak vzniklo 28 poruchových klonů s různými typy jednoznačně specifikovaných defektů. Na těchto poruchových klonech si kdokoliv může okamžitě vyzkoušet své testovací strategie. A pokud bude chtít, může k tomu ihned využít i existující podpůrné prostředky z již proběhlých testování.
Proč došlo k dalšímu vývoji „stejných“ testů?
V předchozím díle jsem si pochvaloval, jak hezky jsem předchozí testy strukturoval a všeobecně vylepšil. Proč jsem se tedy „v tak dokonalém díle“ rozhodl něco vylepšovat? Vodítkem může být jedna věta z perexu již zmíněného předchozího článku: „…kdy jsem se snažil napsat tolik (smysluplných) automatizovaných testů, kolik jen bylo možné“.
Jak se pozná, že počet napsaných smysluplných testů je úplný? No například porovnáním oproti nějaké formě specifikace. Ta ovšem bohužel do té doby chyběla. Což bylo opět další porušení dobrých zásad pro vytváření aplikace (výčet mých dřívějších „hříchů“ je v předchozím díle).
Abych ale nebyl zas tak sebekritický, aplikace byla tehdy specifikována 17 případy užití (use case), ovšem poměrně vágně slovně popsanými – prakticky byly charakterizovány vždy jen jednou větou.
Bylo tedy zřejmé, že pro dosažení kontrolovatelnosti tvrzení „aplikace je plně pokryta testy“ bude nutné vytvořit mnohem podrobnější specifikaci. Termín „specifikace“ je často definován poměrně široce. V tomto textu jím budu označovat dvojici případů užití (use case – UC) a na ně navazujícího seznamu požadavků (requirement – RQM). Tato dvojice pak poslouží k odvození testovacích případů (test case – TC). Při dodržení několika jednoduchých zásad bude možné obousměrné trasování, tj. UC → RQM → TC a naopak TC → RQM → UC. Za těchto podmínek pak bude možné prokázat zmíněné tvrzení „aplikace je plně pokryta testy“.
Vytváření případů užití
Případy užití, jako jeden ze základních diagramů Unified Modelling Language (UML), se sice poměrně snadno a jednotným způsobem kreslí, ovšem chcete-li je podrobněji popsat slovně, je to s tou jednotností slabší. My jsme se nechali inspirovat knihou Cockburn Alistair: Use Cases: Jak efektivně modelovat aplikace. Modifikovali jsme jednu ze zde navržených šablon zápisu UC, kterou jsme následně ještě po různých diskusích s lidmi z praxe několikrát upravovali.
Poznámka: Jistě vás teď napadne jízlivá poznámka typu: „Vždyť autor přece učí software na univerzitě. To tam nemají podrobnou strukturu UC jako součást několika přednášek?“ No, nemáme, respektive neměli jsme. Ale aby ta naše škola nevypadala tak špatně – vy, co jste absolvovali jiné univerzity, zkuste si vzpomenout, zdali jste během studia nějaký detailní UC viděli, případně napsali.
Long story short – postupně jsem připravil (střídání jednotného a množného čísla v tomto článku je správně) z původních 17 UC současných 22 UC. Několikrát jsem je předělával a v průběhu času jsem je mnohokrát opravoval a doplňoval (viz též dále). Výsledek si můžete v případě zájmu prohlédnout. Pokud se vytvářením UC profesně zabýváte, pravděpodobně zjistíte, že používáte trochu (nebo dosti) jinou strukturu zápisu. Jak už jsem zmínil výše, jednotný způsob se nám nepodařilo nalézt.
Ukázka zápisu jednoho UC
UC.01 – Přihlášení do aplikace
Context of Use
Registrovaný uživatel se přihlašuje do aplikace a podle login name jej aplikace přihlásí buď jako studenta nebo jako učitele
Scope
UIS
Level
user goal
Primary Actor
nepřihlášený uživatel
Stakeholders and Interests
● student: chce se přihlásit do aplikace
● učitel: chce se přihlásit do aplikace
Constraints
- uživatelský účet již musí existovat – nelze se nově zaregistrovat
Preconditions
- je zobrazena domácí stránka UIS
- nikdo není přihlášen – horní lišta má černou barvu a na ní je vpravo viditelná položka menu Login
Trigger
uživatel klikne na položku menu Login v horní liště vpravo
Main Success Scenario
- uživatel klikne na položku menu Login v horní liště vpravo
- objeví se stránka Login Page
- uživatel vyplní své již v UIS existující login name
- uživatel zadá heslo pass – pro všechny uživatele stejné heslo
- uživatel stiskne tlačítko Login
Postconditions
- UIS z login name zjistí, zda je uživatel v roli studenta či učitele
- v horní liště vpravo zmizí položka menu Login
- v horní liště je vpravo zobrazeno proklikávatelné jméno a příjmení přihlášeného uživatele
- v horní liště je vpravo zobrazena položka menu Logout
- pro roli studenta je zobrazeno menu Student's View a horní lišta má oranžovou barvu
- pro roli učitele je zobrazeno menu Teacher's View a horní lišta má tmavě zelenou barvu
- pro obě role je zobrazena stránka Overview
Alternative Flows
● 5a. Zadané login name v UIS neexistuje
Postconditions:
● zůstává zobrazena stránka Login Page
● objeví se chybové hlášení o neúspěšném přihlášení
● 5b. uživatel zadal jiné heslo než pass
Postconditions:
● zůstává zobrazena stránka Login Page
● objeví se chybové hlášení o neúspěšném přihlášení
Technology and Data Variations List
N/A
Related Information
● Informaci o všech registrovaných uživatelích lze zobrazit kliknutím na odkaz Database content ze stránky University Information System (Home page)
● pokud je nutné do UIS přidat dalšího uživatele, musí se to provést pomocí importu datového souboru do DB (položka Export/Import DB v horní liště)
Vytváření seznamu požadavků a testovacích případů
Seznamy požadavků (requirements suite – RQS) a seznamy/sady testovacích případů (tests suite – TS) jsou jedním ze způsobů, jak koncepčně připravit množinu testovacích případů (TC). Není to samozřejmě jediný způsob, ale dle mých zkušeností je to jeden ze způsobů, který vede k cíli.
Principiálně se jedná o to, že než začneme „datlovat výkonný kód testů“ (tak, jak jsem to udělal při první verzi testování aplikace), je dobré se nad celým úkolem poměrně obsáhle zamyslet. Zní to jako samozřejmost, ale např. v mém případě tomu tak před dvěma roky nebylo.
Zápisy RQS–RQM a TS–TC už není vhodné „zvládat svépomocí“, jak jsme to učinili v případě výše popsaných UC. Některé nástroje pro plánování a řízení testů (test management system) umožňují s RQM a TC pracovat. Tuto funkcionalitu neposkytují zdaleka všechny existující nástroje, což tedy nepřímo znamená, že mnou používaný postup není jediný možný. Ale některé ano. Ve výuce svého předmětu na testování používám Squash TM, který práci s požadavky a testovacími případy umožňuje. Důvody výběru tohoto nástroje jsou mimo kontext tohoto článku. Podstatné je, že Squash TM dovoluje použít hierarchickou strukturu jak RQS, tak i TS, což významně zpřehlední celkový výsledek.
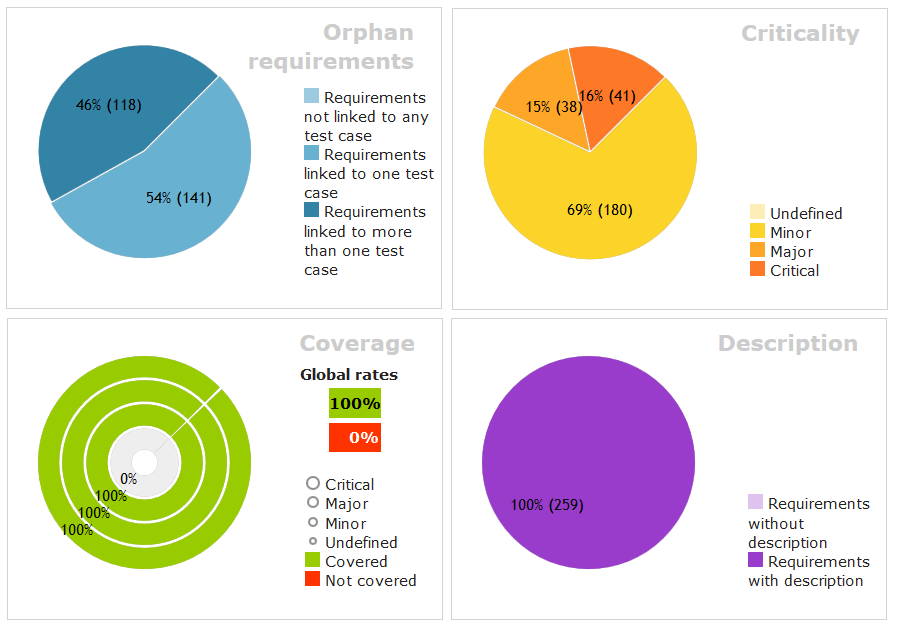
Opět long story short – postupem času jsem vytvořil celkem 259 RQM a na ně navazujících 563 TC. Squash TM umožňuje jejich export a import a též export do Wordu, takže v případě zájmu si je můžete prohlédnout a případně i prakticky ve Squash TM vyzkoušet.
Squash TM umožňuje zobrazit množství vypovídajících grafů, takže jen pro ukázku vybrané charakteristiky RQM (viz též popis dále).
Poznámka: Pokud v grafech marně hledáte nějakou položku (např. v grafu Coverage položku Not covered), pak je správně, že tam není. Tyto agregované grafy ve SquashTM dávají velmi rychlý přehled o tom, co je třeba ještě dodělat. A grafy jsou samozřejmě proklikávací.
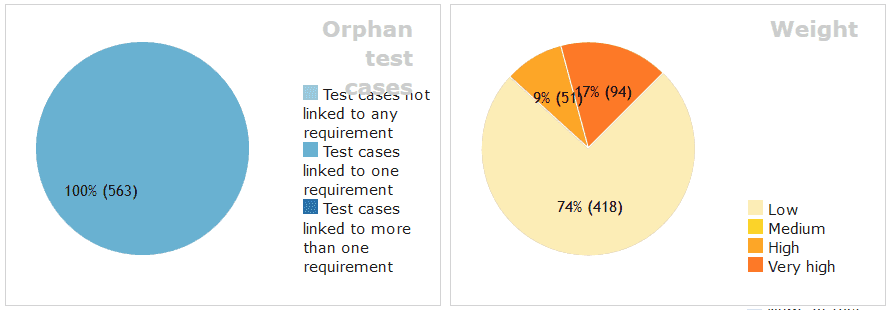
A některé charakteristiky TC:
Poznatky a dobré rady
- Celá příprava zabrala asi dva člověkotýdny. V žádném případě nebyla přímočará, tj. UC → RQM → TC, ale jednotlivé úrovně se ovlivňovaly navzájem.
- V praxi se plně projevilo, jak důležité je se před vlastním programováním testů zamyslet nad celou koncepcí a věnovat tomu odpovídající čas. Vyplatí se to, i když už je testovaná aplikace hotová – to s ohledem na budoucí změny a doplňování (viz dále).
- Jsem si jist, že pokud by se tento postup (tj. UC → RQM → TC) použil od samého začátku vytváření aplikace, dokáží testeři (připravující RQM a TC) významně pozitivně ovlivnit vytvářenou aplikaci. To je naprosto v souladu s tezí, že testování (obecně kontrola kvality) má započnout na samém začátku práce na aplikaci.
- Je vhodné používat také krátké jednotné hierarchické identifikátory, nikoliv jen slovní popisy jednotlivých RQM a TC. Dovoluje to udržovat celou strukturu snadno přehlednou.
V mém případě byly použity čtyři základní úrovně sady požadavků (RQS):- RQS.A – statický obsah všech stránek
- RQS.B – kompletní počáteční stav databáze v aplikaci zobrazené
- RQS.C – pozitivní testy izolovaných jednotlivých akcí (složené/vícekrokové akce byly součástí až akceptačních testů)
- RQS.D – negativní testy
- Squash TM dovoluje obousměrně propojit RQM a TC, což pak umožňuje snadnou kompletní kontrolu správnosti vzájemného provázání a též úplnosti vzájemného pokrytí.
- Již při vytváření RQM je dobré uvažovat o jejich budoucí důležitosti (severity). Od ní se pak samozřejmě bude odvozovat severita TC. Squash TM dovoluje použít pro RQM tři úrovně (neuvažuji implicitní Undefined), ale pro TC už čtyři úrovně. Prakticky jsem přišel na to, že je vcelku snadné dělit do tří úrovní. Snadno jsem totiž stanovil horní a dolní mez, kdy jsem použil rozvahu typu „kritický požadavek“ a naopak „vůbec ne kritický požadavek“. No a ty zbývající jsou mezi nimi. Z tohoto pohledu jsem pak u TC jednu možnou úroveň úplně vynechal.
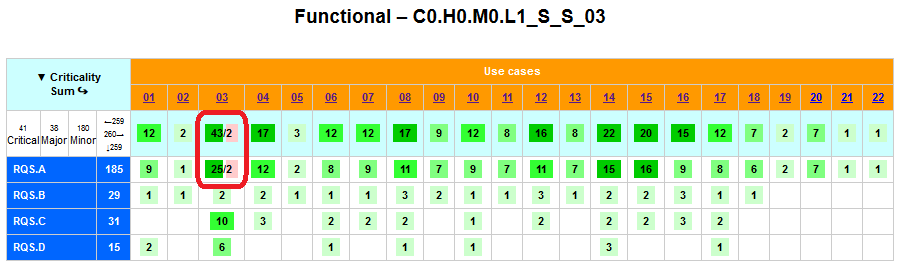
- Po (grafické vizuální) kontrole provázání RQM a TC, kterou Squash TM umožňuje, mi začala chybět možnost grafické kontroly provázání RQM na UC. Ta informace v RQM byla zapsána, ale postupné jednotlivé manuální kontroly jsou náchylné k chybám. Napsal jsem si proto program, který tyto závislosti vizualizuje v HTML. Po nastylování a doplnění možnosti rozličných sbalení a rozbalení (díky kolegovi) se tento HTML stal významným pomocníkem při různých kontrolách (viz též dále).
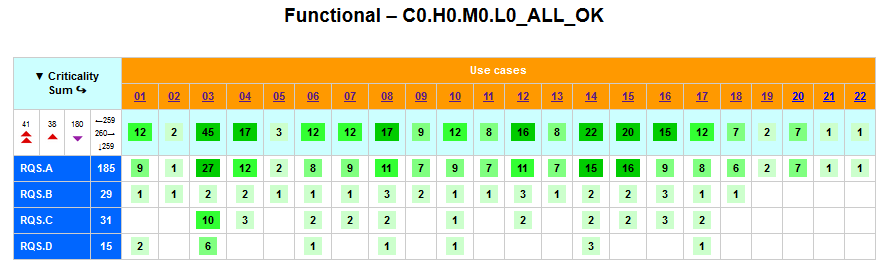
- Dodatečně jsem z RQM ubral „nadbytečné“ provázání na „vedlejší“ UC. Prakticky to znamená, že se mi osvědčil stav, kdy by se jeden RQM měl vztahovat k právě jednomu „svému hlavnímu“ UC a nic víc. Takže např. RQM.B.03.01 – student’s table My Subjects, pokrývá jen UC.04 (práce s touto webovou stránkou a tabulkou), byť by mohl pokrývat i „vedlejší“ UC.01 (před dosažením stránky je nutný login).
Toto ubrání není až tak důležité při kontrole pokrytí RQM → UC, ale bude důležité při zobrazení selhaných testů. To je zobrazeno ve stejném typu tabulky a v případě, že výše zmíněný test tabulky My Subjects selže, odkazoval by „falešně“ i na selhání loginu.
Programování vlastních testů
Teoreticky by se mohlo stát, že by množina testů připravených v předchozí iteraci (cca před rokem) byla totožná s množinou testovacích případů získaných výše popsanou analýzou RQM a TC. To by prakticky znamenalo, že jsem předtím i bez existující specifikace jasnozřivě naprogramoval plné pokrytí testy. To se samozřejmě nestalo, protože důkladná analýza nalezla – dle očekávání – více testovacích případů.
Nutno ale poznamenat, že některé TC získané analýzou pak nebylo možné naprogramovat (speciality překračující rámec tohoto článku), takže byla nutná zpětná úprava textů TC a případně i RQM ve Squash TM. Prostě celý proces testování není přímočarý, ale skutečně iterativní. Naštěstí jej značně usnadňují a zpřehledňují použité technologie a nástroje.
Poznámka: Použití těchto nástrojů samozřejmě není „zadarmo“. Je potřeba značné počáteční investice v podobě úsilí a času. Pro jednorázové testy (běžné aplikace) by se celá akce zcela určitě nevyplatila. Ovšem pokud by se jednalo o aplikaci s předpokládaným dalším vývojem, pak si dovolím tvrdit, že se zmíněné úsilí vyplatí. Toto mé přesvědčení vyplývá jednak z „mého dobrého pocitu po dokončení akce“, že je ve všem pořádek a je to (s rozumnou mírou úsilí) zdokumentováno. Neméně důležitý je i fakt, že další rozšiřování aplikace a tudíž i jejích testů bude řízené. Samozřejmě, při rozšiřování aplikace nelze dopředu tvrdit, že rozšíření neovlivní stávající testy. Ale pokud to nastane, pak se též díky dobré dokumentaci mnohem snadněji naleznou problematické závislosti. Rozšiřování spektra pouze testů (viz dále) by mělo být z hlediska ovlivnění stávajících testů zcela bezproblémové.
Při psaní vlastních testů jsem samozřejmě používal již vytvořenou knihovnu Support pro práci s aplikací pomocí Selenium WebDriveru.
Při programování TC, které byly oproti předchozí verzi navíc, se plně projevila výhoda konceptu PageObject. Doplňování chybějící funkcionality ovládání webových stránek bylo zcela přímočaré a bezproblémové. Nedokáži si představit, že bych toto rozšiřování funkčnosti zvládl tak rychle a snadno s dřívějším přístupem bez PageObject.
Poznámka: V této fázi již začínal psát kolega své akceptační testy pomocí RobotFrameworku, ovšem též s využitím knihovny Support. A samozřejmě i on měl požadavky na změnu či rozšíření její funkčnosti. I zde její úprava proběhla naprosto „bezešvě“ – je třeba si uvědomit, že knihovna Support pak byla souběžně využívána dvěma různými typy testů.
Díky jednotným identifikátorům TC (viz výše) bylo možné dodatečně zpracovávat logy proběhlých testů a v případě testování poruchových klonů pak generovat HTML soubory ukazující pokrytí RQM na UC včetně nalezených problémů. Tato grafická reprezentace chyb výrazně zpřehlednila kontrolu, zda testy opravdu selhávají na očekávaných místech injektovaných defektů.
Rozsahy a počty testů
Můžete si prohlédnout podrobnou tabulku. Opět z ní vyplývá, že rozsahy testů jsou více než dvojnásobné oproti rozsahu testované aplikace.
Celkový počet provedených testů je 1 245, ale to není úplně vypovídající číslo. Jak již bylo uvedeno výše, je celkový počet TC 563 – to je počet metod v Javě anotovaných @Test (případně podobnou anotací @TestTemplate či @ParametrizedTest). Ale množství z těchto testů jsou parametrizované testy a některé využívají více assertů. Takže lépe vypovídající hodnota o rozsahu testování je právě počet provedených assertů a těch bylo 7 493.
Možné rozšiřování sady testů
Uvedený postup umožňuje velmi přímočaré rozšíření testovací sady dle později vzniklých požadavků. Pokusím se to uvést na konkrétním případě.
Teprve nedávno jsem zjistil, že Selenium umožňuje testovat i použité barvy webových elementů. To jsem dříve netušil a tato možnost by mi dovolila rozšířit existující sadu funkcionálních testů. A tím např. nalézt specifický injektovaný defekt v poruchovém klonu.
Pokusil jsem se převést tyto smělé plány v činy – koncept výsledku si můžete v případě zájmu prohlédnout na Git ve větvích color-1-7 pro knihovnu Support i pro vlastní testy. Příprava a vyzkoušení celého konceptu včetně ověření na poruchovém klonu mi zabrala asi půl dne. Dle mého odhadu by kompletní práce na doplnění tohoto – principiálně zcela nového – typu testů podle následujících bodů zabrala asi dva dny.
Postupoval bych (body 1. až 4. jsem při ověřování konceptu neprováděl) následovně:
- UC by přidáním nového testu rozhodně nebyly ovlivněny, tj. zůstaly by beze změny.
- V RQM by nové testy patřily jednoznačně do skupiny RQS.A – statický obsah všech stránek. To znamená, že bych si prohlížel aplikaci a hledal, kde všude má barva webových elementů skutečný význam (tj. záhlaví rozlišující studenta od učitele, tlačítka, specifické řádky v tabulce, hlášení o výsledku provedené operace atp.).
Nalezené elementy bych průběžně ve Squash TM popsal v rozšíření příslušných RQM.A.x.y. - Například současný RQS.A.04 header of logged user, má nyní čtyři RQM:
- RQM.A.04.01—menu element University Information System
- RQM.A.04.02—menu element Home
- RQM.A.04.03—menu element Logout
- RQM.A.04.04—menu element First name and last name
- Pokračoval bych dále v doplňování ve Squash TM pro odpovídající TS a TC, takže bych doplnil např.: TS.A.04.05—color of background a TC.A.04.05.01—color
Opět s příslušnými popisy a severitami a provázal bych TC s příslušnými RQM. - V knihovně Support ve třídě
UisTagsjsem zavedl nový tagCOLORpro tento typ testů. - Ve třídě
Constjsem zavedl konstanty pro typy barev, tj. barva pro tlačítko typu update, delete, cancel apod. což by do budoucna zjednodušilo případné úpravy. Přitom jsem ale zjistil, že ne všechny barvy tlačítek jsou v aplikaci používány konzistentně. Toto odhalení lze považovat za další výhodu komplexního testování. Náprava stavu bude provedena při příštím upgrade aplikace UIS. - V Support jsem v příslušných třídách PageObject jednotlivých webových stránek (nebo jejich částí) příslušným webovým elementům přidal metody typu
String getButtonXYColor(). - V Support jsem průběžně psal JUnit testy na tyto jednotlivé
getBgColorButtonXY()metody, čímž jsem ihned ověřoval funkčnost konceptu. - V Support ve třídě
Checkjsem přidal metoducheckColor()pro zajištění jednotného způsobu testování a logování případných chybových výpisů. - V projektu funkcionálních testů jsem do odpovídající třídy (vím, kde je v poruchovém klonu defekt)
TS_A_11_05přidal metodu s@DisplayName(“TC.A.11.07.04: button <Participants> - bgColor“)
V těle metody se volánímgetBgColorParticipantsButton()z příslušného PageObject získá existující barva a volánímcheckColor()se ověřuje její správnost.
Při tomto postupu je v každém kroku jasně dáno do jakého místa – ať již specifikace ve Squash TM nebo ve zdrojových kódech – bude prováděna úprava či doplnění. Jedná se tedy o přímočarou aktivitu. Samozřejmě se při kódování vyskytly nějaké problémy (např. barva transparent), ale byly jasně izolované a tudíž i poměrně lehce odstranitelné.
Velmi důležitým krokem jsou jednotkové testy jakéhokoliv zásadnějšího (když jednotkový test ověří, že koncept funguje pro jedno tlačítko, není třeba jej ověřovat pro principiálně stejný typ tlačítka) doplnění knihovny Support. Tímto způsobem jsem doplnil testování barev textu i pozadí u všech existujících typů tlačítek – v liště, v tabulkách, v dialogových oknech. Po provedeném ověření konceptu by celkové doplnění (tj. do všech příslušných webových stránek) představovalo víceméně mechanickou činnost.
Další výhoda celého přístupu je v tom, že všechny zmíněné akce nijak neovlivňovaly jakékoliv dříve vytvořené testy.
Poznámka: Proč jsem toto dosud provedl pouze v konceptu a nedotáhl jsem celou akci do konce, tj. nevěnoval jsem tomu další den a půl? Protože není problém výše popsané doplnění knihovny Support a testů. A problém není ani doplnění příslušných RQM a TC do Squash TM. Ale je časově velmi náročné novou sadou testů otestovat všech 28 poruchových klonů (plus jeden bezporuchový), vygenerovat a vyhodnotit výsledky a všechny tyto změny konzistentně zahrnout do rozsáhlé a vzájemně provázané webové dokumentace celého projektu. Takže s tím počkám na nějakou další větší změnu celé aplikace.
Shrnutí a závěr
Popsaný způsob testování neodhalil v testované aplikaci žádné další defekty oproti předchozímu způsobu. Ovšem při systematické přípravě UC, RQM a TC bylo navrženo asi dvacet minoritních vylepšení aplikace UIS. Tato vylepšení byla do aplikace zapracována a nově vzniklou sadou testů otestována.
Hlavní význam celé akce však byl v tom, že byl do psaní testů zaveden od samého začátku pořádek. Tím se také zvýšila důvěryhodnost tvrzení o pokrytí aplikace testy. Jednoznačně mohu říci, že se vyplatí před zahájením kódování testů věnovat čas pečlivé analýze testů včetně jejich veškeré dokumentace. Psaní (tj. kódování) vlastních testů to následně urychlí.
Určitě existují i jiné postupy plánování a analýzy, než zde popsaná metoda UC → RQM → TC, ovšem nemám s nimi zkušenosti. Popsaná metoda pro tuto aplikaci zcela splnila svůj účel.
Rozhodně se vyplatí používat nějaký nástroj pro plánování a řízení testů (v mém případě Squash TM). Ideálně ten, který je provázaný na nástroj řízení chybových reportů (bug report system – v mém případě Mantis BT).
Nástroje typu Squash TM jednak pomáhají udržovat pořádek a v grafických přehledech upozorňují rychle na různé relikty, kdy není něco pokryto. Dále pak při probíhajících testováních dokáží snadno generovat nejrůznější přehledy a grafy o celkovém postupu testování v čase. Ty nebyly v mém případě potřebné (aplikace již byla odladěna a všechny testy proběhly „naráz“), ale v reálném případě by představovaly důležitou informaci o průběžném zvyšování kvality testovaného produktu.
Přestože bylo popsané testování velmi důkladné, souběžně prováděné akceptační testování (viz následující článek) odhalilo v testované aplikaci dvě (velmi specifické) chyby. Jejich popis bude uveden v následujícím díle. Tím se potvrdila užitečnost tzv. testovacího mixu. Nebo jinak – potvrdila se existence pesticidového paradoxu. Pesticidový paradox je stav, kdy sada testů neodhaluje určité selhání, ale aplikace defekty způsobující toto selhání obsahuje.

Popsanými testy bylo otestováno všech 28 existujících poruchových klonů. To také ověřilo validitu testů, protože jsem zpětně kontroloval, zda testy odhalují očekávaná selhání.
V příštím díle se v případě zájmu dočtete, jak jsme psali akceptační testy pomocí Robot frameworku.